Selective association rule generation
Mining association rules is a popular and well researched method for discovering interesting relations between variables in large databases. A practical problem is that at medium to low support values often a large number of frequent itemsets and an …
Authors: Michael Hahsler, Christian Buchta, Kurt Hornik
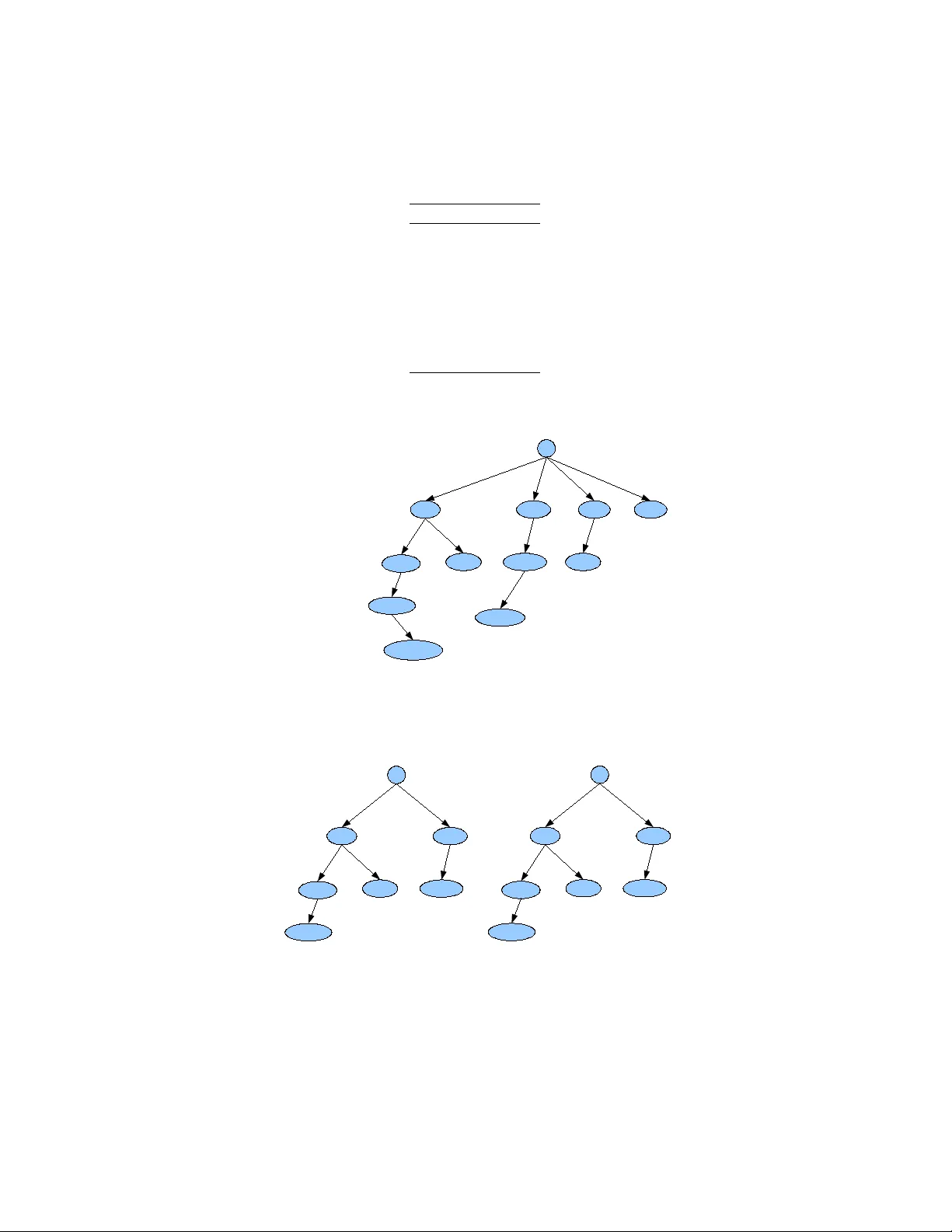
Selectiv e Asso ciation Rule Generation Mic hael Hahsler and Christian Buc hta and Kurt Hornik Septem b er 26, 2018 Abstract Mining asso ciation rules is a popular and well researc hed metho d for disco vering interesting relations b et ween v ariables in large databases. A practical problem is that at medium to low supp ort v alues often a large n umber of frequent itemsets and an even larger n umber of asso ciation rules are found in a database. A widely used approach is to gradually increase minimum supp ort and minim um confidence or to filter the found rules using increasingly strict constraints on additional measures of inter- estingness until the set of rules found is reduced to a manageable size. In this pap er we describ e a different approach which is based on the idea to first define a set of “in teresting” itemsets (e.g., by a mixture of mining and expert kno wledge) and then, in a second step to selectiv ely generate rules for only these itemsets. The main adv antage of this approac h ov er increasing thresholds or filtering rules is that the num b er of rules found is significantly reduced while at the same time it is not necessary to in- crease the supp ort and confidence thresholds which might lead to missing imp ortan t information in the database. 1 Motiv ation Mining asso ciation rules is a popular and well researched metho d for dis- co vering in teresting relations b et ween v ariables in large databases. Piatetsky- Shapiro (1991) describes analyzing and presenting strong rules discov ered in databases using different measures of interestingness. Based on the con- cept of strong rules, Agraw al et al. (1993) in tro duced asso ciation rules for disco vering regularities betw een pro ducts in large scale transaction data recorded by p oin t-of-sale systems in sup ermark ets. F or example, the rule { onions , v egetables } ⇒ { b eef } found in the sales data of a sup ermark et w ould indicate that if a customer buys onions and v egetables together, he or she is likely to also buy b eef. Suc h information can be used as the basis for decisions ab out mark eting activities suc h as, e.g., promotional pricing or product placements. T o da y , asso ciation rules are emplo yed in man y application areas including W eb usage pattern analysis (Sriv astav a et al. 2000), intrusion detection (Luo & Bridges 2000) and bioinformatics (Creighton & Hanash 2003). 1 F ormally , the problem of mining asso ciation rules from transaction data can be stated as follo ws (Agra wal et al. 1993). Let I = { i 1 , i 2 , . . . , i n } b e a set of n binary attributes called items . Let D = { t 1 , t 2 , . . . , t m } b e a set of transactions called the datab ase . Each transaction in D has a unique transaction ID and contains a subset of the items in I . A rule is defined as an implication of the form X ⇒ Y where X, Y ⊆ I and X ∩ Y = ∅ . The sets of items (for short itemsets ) X and Y are called ante c e dent (left- hand-side or LHS) and c onse quent (righ t-hand-side or RHS) of the rule, resp ectiv ely . T o select in teresting rules from the set of all p ossible rules, constraints on v arious measures of significance and strength can b e used. The b est- kno wn constrain ts are minimum thresholds on supp ort and confidence. The supp ort of an itemset is defined as the proportion of transactions in the data set whic h contain the itemset. All itemsets which ha ve a supp ort ab o ve a user-sp ecified minim um supp ort threshold are called fr e- quent itemsets . The c onfidenc e of a rule X ⇒ Y is defined as conf ( X ⇒ Y ) = supp( X ∪ Y ) / supp( X ). This can b e interpreted as an estimate of the probability P ( Y | X ), the probability of finding the RHS of the rule in transactions under the condition that these transactions also contain the LHS (e.g., Hipp et al. 2000). Asso ciation rules are required to satisfy a user-specified minimum sup- p ort and a user-sp ecified minim um confidence at the same time. Asso cia- tion rule generation is alw ays a t w o-step pro cess. First, minim um supp ort is applied to find all frequent itemsets in a database. In a second step, these frequen t itemsets and the minimum confidence constraint are used to form rules. A t medium to low supp ort v alues, usually a large num b er of frequent itemsets and an even larger num ber of asso ciation rules are found in a database whic h makes analyzing the rules extremely time consuming or ev en imp ossible. Several solutions to this problem were prop osed. A prac- tical strategy is to either increase the user-sp ecified supp ort or confidence threshold to reduce the num b er of mined rules. It is also p opular to filter or rank found rules using additional interest measures (e.g., the measures analyzed b y T an et al. (2004)). How ever, increasing thresholds and filter- ing rules till a manageable num b er is left can lead to the problem that only already ob vious and well-kno wn rules are found. Alternativ ely , each rule found can b e matched against a set of exp ert- generated rule templates to decide whether it is interesting or not (Klemet- tinen et al. 1994). F or the same purpose, Imielinski & Virmani (1998) describ e a query language to retrieve rules matching certain criteria from a large set of mined rules. A more efficient approac h is to apply addi- tional constrain ts on item appearance or on additional interest measures already during mining itemsets (e.g., Bay ardo et al. 2000, Srik an t et al. 1997). With this technique, the time to mine large databases and the num- b er of found itemsets can significan tly be reduced. The popular Apriori implemen tation by Borgelt (2006) as w ell as some commercial data min- ing to ols pro vide a similar mechanism where the user can sp ecify which items hav e to or cannot b e part of the LHS or the RHS of the rule. In this paper w e discuss a new approac h. Instead of treating mining asso ciation rules from transaction data as a single tw o-step pro cess where 2 ma yb e the structure of rules can b e specified (e.g., b y templates), we completely decouple rule generation from frequen t itemset mining in order to gain more flexibility . With our approach, rules can be generated from an arbitrary sets of itemsets. This giv es the analyst the p ossibilit y to use an y metho d to define a set of “in teresting” itemsets and then generate rules from only these itemsets. In teresting itemsets can b e the result of using a mixture of additional constrain ts during mining, arbitrary filtering op erations and exp ert kno wledge. 2 Efficien t selectiv e rule generation F or conv enience, w e introduce X = { X 1 , X 2 , . . . , X l } for sets of l itemsets. Analogously , w e define R for sets of rules. Generating asso ciation rules is alw ays separated in to tw o tasks, first, mining all frequent itemsets X f and then generating a set of rules R from X f . Extensiv e research exists for the first task (see, e.g., Hipp et al. 2000, Go ethals & Zaki 2004), therefore, we concentrate in the follo wing on the second task, the rule generation. In the general case of rules with an arbitrary size of the rule’s right- hand-side, for each itemset Z ∈ X with size k w e hav e to chec k confidence for 2 k − 2 rules Z \ Y ⇒ Y resulting from using all non-empt y prop er subsets Y of Z as a rule’s RHS. F or sets with large itemsets this clearly leads to an enormous computational burden. Therefore, most implemen- tations and also this pap er follows the original definition of Agraw al et al. (1993) who restrict Y to single items, whic h reduces the problem to only k chec ks for an itemset of length k . The rule generation engine for the p opular Apriori algorithm (e.g., the implementation by Borgelt (2003, 2006)) efficiently generates rules by reusing the data structure built lev el-wise during coun ting the support and determining the frequent itemsets. The data structure contains all supp ort information and provides fast access for calculating rule confidences and other measures of interestingness. If a set of itemsets X is generated by some other means, no such data structure might be av ailable. Since the do wnw ard-closure prop ert y of supp ort (Agraw al & Srik an t 1994) guarantees that for a frequent itemset also all its subsets are frequen t, the data structure can b e rebuilt from a complete set of all frequent itemsets and their supp ort v alues. Ho wev er, the aim of this paper is to efficiently induce rules from an arbitrary set of itemsets which, e.g., could be sp ecified by an exp ert without the help of a data mining tool. In this case, the supp ort information needed to calculate confidence is not a v ailable. F or example, if all av ailable information is an itemset con taining five items and it is desired to generate all p ossible rules con taining all items of this itemset, the support of the itemset (which w e migh t know) and the supp orts of all its subsets of length four are needed. This missing support information has to b e obtained from the database. A simple method w ould b e to reuse an implemen tation of the Apriori algorithm with the support of the least frequen t itemset in X . If this supp ort is known, X f ⊇ X will be found. Otherwise, the user has to iterativ ely reduce the minimum supp ort till the found X f con tains all 3 itemsets in X . The rule generation engine will then produce the set of all rules which can be generated for all itemsets in X f . F rom this set all rules whic h do not stem from the itemsets in X hav e to b e filtered, leaving only the desired rules. Ob viously , this is an ineffective metho d whic h p oten tially generates an enormous num b er of rules of whic h the ma jority has to b e filtered, representing an additional large computational effort. The problem can b e reduced using several restrictions. F or example, we can restrict the maximal length of frequent itemsets to the length of the longest itemset in X . Another reduction of computational complexity can b e ac hieved by removing all items whic h do not o ccur in an itemset in X from the database before mining. How ev er, this pro cess is still far from b eing efficient, esp ecially if man y itemsets in X share some items or if X con tains some very infrequent itemsets. T o efficiently generate rules for a given confidence or other measure of rule strength from an arbitrary set of itemsets X the follo wing steps are necessary: 1. Count the supp ort v alues eac h itemset X ∈ X and the subsets { X \ { x } : x ∈ X } needed for rule generation in a single pass ov er the database and store them in a suitable data structure. 2. Populate set R b y selectiv ely generating only rules for the itemsets in X using the supp ort information from the data structure created in step 1. This approach has the adv an tage that no expensive rule filtering is necessary and that com binatorial explosion due to some very infrequent itemsets in X is av oided. The data structure for the needed support coun ters needs to pro vide fast access for coun ting and retrieving the support counts. A suitable data structure is a prefix tree (Knuth 1997). Typically , prefix trees are used in frequen t itemset mining as condensed representations for the databases. Here the items in transactions are lexically ordered and each no de contains the occurrence counter for a prefix in the transactions. The no des are organized suc h that no des with a common prefix are in the same subtree. The database in T able 1 is represented b y the prefix tree in Figure 1 where eac h no de contains a prefix and the coun t for the prefix in the database. F or example, the first transaction { a, b, c } w as resp onsible for creating (if the nodes did not already exist) the no des with the prefixes a , ab and abc and increasing eac h node’s coun t b y one. Although adding transactions to a prefix tree is very efficien t, obtaining the counts for itemsets from the tree is exp ensiv e since several no des ha ve to be visited and their coun ts hav e to b e added up. F or example, to retrieve the support of itemset X = { d, e } from the prefix tree in Figure 1, all no des except abce , bce and e hav e to b e visited. Therefore, for selectiv e rule generation, where the coun ts for individual itemsets ha v e to b e obtained, using such a transaction prefix tree is not very efficient. F or selective rule generation we use a prefix tree similar to the itemset tree describ ed b y Borgelt & Kruse (2002). How ever, w e do not generate the tree level-wise, but we first generate a prefix tree which only contains the no des necessary to hold the coun ters for all itemsets which need to 4 TID Items 1 { a, b, c } 2 { b, c, e } 3 { e } 4 { a, b, c, e } 5 { b } 6 { a, c } 7 { d, e } 8 { a, b } T able 1: Example database a: 4 d:1 ab: 3 e: 1 a b d e b c c bc: 1 c bce :1 e de: 1 e abc e:1 e abc :2 b:2 ac: 1 Figure 1: Prefix tree as a condensed represen tation of a database. a: 0 ab: 0 a b b c c bc: 0 c abc :0 b:0 ac: 0 a: 4 ab: 3 a b b c c bc: 3 c abc :2 b:4 ac: 3 (a) (b) Figure 2: Prefix tree for itemset counting. (a) con tains the empty tree to count the needed itemsets for rules con taining { a, b, c } and (b) con tains the counts. 5 count ( t, p ) 1 if t.siz e > 0 2 then n ← successor ( t [1] , p ) 3 if n 6 = nil 4 then n.counter ++ 5 count ( t [2 . . . k ] , n ) 6 count ( t [2 . . . k ] , p ) 7 return T able 2: Recursive itemset counting function b e counted. F or example, for generating rules for the itemset { a, b, c } , we need to coun t the itemset and in addition { a, b } , { a, c } and { b, c } . The corresp onding prefix tree is shown in Figure 2(a). The tree contains the no des for the itemsets plus the necessary no des to make it a prefix tree and all counters are initialized with zero. Note that with an increasing n umber of itemsets, the growth of no des in the tree will decrease since itemsets typically share items and th us will also share no des in the tree. After creating the tree, w e coun t the itemsets for each transaction using the recursive function in T able 2. The function count ( t, p ) is called with a transaction (as an array t [1 . . . k ] representing a totally ordered set of items) and the ro ot no de of the prefix tree. Initially , w e test if the transaction is empt y (line 1) and if so, the recursion is done. In line 2, w e try to get the successor node of the current no de that corresp onds to the first item in t . If a no de n is found, we increase the no de’s counter and contin ue recursiv ely coun ting with the remainder of the transaction (lines 4 and 5). Otherwise, no further coun ting is needed in this branch of the tree. Finally , we recursiv ely count the transaction with the first elemen t remov ed also into the subtree with the ro ot no de p (line 6). This is necessary to count all itemsets that are co vered b y a transaction. F or example, counting the transaction { a, b, c, e } in the prefix tree in Figure 2 increases the nodes a , ab , abc , ac , b , and bc by one. There are sev eral options to implement the structure of an n -ary prefix tree (e.g., each node con tains an array of p oin ters or a hash table is used). In the implemen tation used for the exp erimen ts in this paper, w e use a link ed list to store all direct successors of a node. This structure is simple and memory-efficient but has the price of an increased time complexit y for searc hing a successor node in the recursive itemset counting function (see line 2 in T able 2). Ho wev er, this drawbac k can b e mitigated b y first ordering the items b y their in v erse item-frequency . This mak es sure that items which o ccur often in the database are alwa ys placed near to the b eginning of the link ed lists. After coun ting, the support for each itemset is contained in the node with the prefix equal to the itemset. Therefore, we can retriev e the needed supp ort v alues from the prefix tree and generating the rules is straight forw ard. 6 Adult T10I4D100K POS Source questionnaire artificial e-commerce T ransactions 48,842 100,000 515,597 Mean transaction size 12.5 10.1 6.5 Median transaction size 13.0 10.0 4.0 Distinct items 115 870 1,657 Min. supp ort 0.002 0.0001 0.00055 Min. confidence 0.8 0.8 0.8 F requent itemsets 466,574 411,365 466,999 Rules 1.181,893 570,908 361,593 T able 3: The used data sets. 3 Exp erimen tal results W e implemented the prop osed selectiv e rule generation pro cedure using C co de and added it to the R pack age arules (Hahsler et al. 2007) 1 . T o examine the efficiency w e use the three different data sets shown in T a- ble 3. The A dult data set w as extracted b y Koha vi (1996) from the cen- sus bureau database in 1994 and is av ailable from the UCI Rep ository of Machine Learning Databases (Newman et al. 1998). The con tinuous attributes w ere mapp ed to ordinal attributes and each attribute’s v alues w as coded by an item. The recoded data set is also included in pac k age arules. T10I4D100K is an artificially generated standard data set using the pro cedure presented b y Agraw al & Srik ant (1994) which is used for ev aluation in many pap ers. POS is an e-commerce data set con taining sev eral years of p oint-of-sale data which was pro vided by Blue Martini Soft ware for the KDD Cup 2000 (Koha vi et al. 2000). The size of these three data sets v aries from relativ ely small with less than 50,000 transac- tions and ab out 100 items to more than 500,000 transactions and 1,500 items. Also the sources are diverse and, therefore, using these data sets should provide insights into the efficiency of the prop osed approach. W e compare the running time b eha vior of the proposed rule genera- tion method with the highly optimized Apriori implementation by Borgelt (2006) whic h pro duces association rules. F or Apriori, w e use the following settings: • Instead of the support stated in T able 3, w e use the smallest support v alue of an itemset in X as the minim um supp ort constraint and we restrict mining to itemsets no longer than the longest itemset in X . Also, w e remo ve all items which do not o ccur in X from the database prior to mining. These settings significantly reduce the search space and therefore also Apriori’s execution time. How ever, it has to b e noted that setting the minimum supp ort requires that the supp ort of all itemsets in X is known. This is not the case if some itemsets 1 The source co de is freely av ailable and can b e downloaded together with the pack age arules from http://CRAN.R- project.org . Selectiv e rule generation was added to arules in version 0.6-0. 7 in X are defined b y an exp ert without mining the database. In this case, one w ould hav e to use trial and error to find the optimal v alue. • F or the comparison, w e omit the exp ensiv e filter op eration to find only the rules stemming from X . Therefore, using Apriori for selec- tiv e rule generation will take more than the reported time. T o generate for eac h data set a p ool of in teresting itemsets, w e mine frequen t itemsets with a minimum support such that w e obtain betw een 400,000 and 500,000 itemsets (see T able 3). F rom this p o ol, we take random samples which represen t the sets of itemsets X w e wan t to pro duce rules for. W e use a minimum confidence of 0.8 for all experiments. W e v ary the size of X from 1 to 20,000 itemsets, rep eat the procedure for eac h size 100 times and report the av erage execution times for the three data sets in Figures 3 to 5. F or Apriori, the execution time reaches a plateau already for a few 100 to a few 1000 itemsets in X and is then almost constant, for all data sets considered. At that point Apriori already efficiently mines all rules up to the smallest necessary minim um supp ort and the specified minim um confidence. The running time of the selective rule generation increases sub-linearly with the num b er of interesting itemsets. The increase results from the fact that with more itemsets in X , the prefix tree increases in size and therefore the counting pro cedure has to visit more no des and gets slow er. The increase is sub-linear b ecause with an increasing n umber of itemsets the c hances increase that several itemsets share no des which slo ws do wn the growth of the tree size. Figures 3 to 5 sho w that for up to 20,000 itemsets in X , the selectiv e rule generation is usually m uch faster than mining rules with Apriori ev en though the expensive filtering pro cedure w as omitted. Only on the Adult data set the proposed metho d is slow er than Apriori for more than about 18,000 itemsets in X . The reason is that at some point, the prefix tree for coun ting contains to o man y notes and performance deteriorates compared to the efficient level-wise counting of all frequent itemsets employ ed by Apriori. The selective rule generation pro cedure represents an significan t im- pro vemen t for selectively mining rules for a small set of (a few thousand) in teresting itemsets. On the mo dern desktop PC (we used a single core of an In tel Core2 CPU at 2.40 GHz), the results can be found t ypically under one second while using Apriori alone without filtering takes already sev- eral times that long. This impro vemen t of getting results almost instantly is crucial since it enables the analyst to in teractively examine data. 4 Application example As a small example for the application of selectiv e rule generation, we use the Mushro om data set (Newman et al. 1998) which describes 23 sp ecies of gilled mushrooms in the Agaricus and Lepiota family . The data set contains 8124 examples describ ed by 23 nominal-v alued attributes (e.g., cap-shape, o dor and class (edible or p oisonous)). By using one binary v ariable for eac h p ossible attribute v alue to indicate if an example 8 0 5000 10000 15000 20000 0 1 2 3 4 5 6 Adult Number of itemsets Time [sec.] Selective generation Apriori Figure 3: Running time for the Adult data set. 0 5000 10000 15000 20000 0 1 2 3 4 5 6 T10I4D100K Number of itemsets Time [sec.] Selective generation Apriori Figure 4: Running time for the T10I4D100K data set. 9 0 5000 10000 15000 20000 0 5 10 15 20 25 POS Number of itemsets Time [sec.] Selective generation Apriori Figure 5: Running time for the POS data set. p ossesses the attribute v alue, the 23 attributes are recoded in to 128 binary items. Using traditional tec hniques of asso ciation rule mining, an analyst could pro ceed as follo ws. Using a minim um supp ort of 0.2 results in 45,397 frequent itemsets. With a minim um confidence of 0.9 this gives 281,623 rules. If the analyst is only in terested in rules whic h indicate edibilit y , the follo wing rule inclusiv e template can be used to filter rules: an y attribute* ⇒ an y class F ollowing the notation b y Klemettinen et al. (1994), the LHS of the template means that it matches any combination of items for an y attribute and the RHS only matches the tw o items derived from the attribute class ( class=edible and class=poisonous ). Using the rule template to filter the rules reduces the set to 18,328 rules whic h is clearly too large for visual insp ection. F or selective rule generation introduced in this paper, the exp ert can decide which itemsets are of interest to gain new insights into the data. F or example, the concept of fr e quent close d itemsets can b e used to select in teresting itemsets. Using frequent closed itemsets is an approach to reduce the n umber of mined itemsets without loss of information. An itemset is closed if no prop er sup erset of the itemset is contained in eac h transaction in which the itemset is con tained (Pasquier et al. 1999, Zaki 2004). F requen t closed itemsets are a subset of frequent itemsets whic h preserv e all supp ort information a v ailable in frequent itemsets. Often the set of all frequent closed itemsets is considerably smaller than the set of all frequent itemsets and thus easier to handle. 10 Mining closed frequen t itemsets on the Mushroom data set with a minim um support of 0.2 results in 1231 itemsets. By generating rules only for these itemsets we get 4688 rules. Using the rule template as ab o v e leav es 154 rules, whic h are wa y more manageable than the more than 100 times larger set obtained from just using frequent itemsets. T o compare the sets of rules from the set of frequent itemsets with the rules from the reduced set of (frequent closed) itemsets, w e sort the found rules in descending order first by confidence and then b y supp ort. In T ables 4 and 5 we insp ect the first few rules of eac h set. F or the rules generated from frequent itemsets (T able 4) we see that rules 1 and 2, and also rules 3 to 5 each hav e exactly the same v alues for supp ort and confidence. This can b e explained b y the fact that only items are added to the LHS of the rules which are also con tained in ev ery transaction the item in the LHS are contained in. F or example, for rule 2 the item veil-type=partial is added to the LHS of rule 1. Dep ending on the t yp e of application the rules are mined for, one of the rules is redundant. If the aim is prediction, the shorter rule suffices. If the aim is to understand the structure of the data, the longer rule is preferable. F or rules 3 to 5 the redundancy is even bigger. Insp ecting the rest of the rules rev eals that for rule 3 a total of 38 redundant rules are contained in the set. Using closed frequen t itemsets av oids suc h redundancies while retain- ing all information whic h is presen t in the set of rules mined from frequen t itemsets. F or example, for the tw o redundant rules (rules 1 and 2 in T a- ble 4) the first rule with {odor=none, gill-size=broad, ring-number=one} in the LHS is not present in T able 5. The second rule in T able 5 cov ers rules 3 to 5 in T able 4 plus 35 more rules (not sho wn in the table). Using closed frequent itemsets is just one option. Using selective rule generation, the exp ert can define arbitrary sets of in teresting itemsets to generate rules in an efficien t w ay . 5 Conclusion Mining rules not only for sets of frequent itemsets but from arbitrary sets of possibly even relativ ely infrequent itemsets can b e helpful to concen- trate on “interesting” itemsets. F or this purpose, we described in this pap er how to decouple the pro cesses of frequent itemset mining and rule generation b y prop osing an procedure which obtains all needed informa- tion in a self-contained selective rule generation process. Since selectiv e rule generation do es not rely on finding frequent itemsets using a min- im um supp ort threshold, generating itemsets from itemsets with small supp ort do es not result in combinatorial explosion. Exp erimen ts with several data sets show that the proposed pro cess is efficien t for small sets of interesting itemsets. Unlik e existing methods based on frequent itemset mining, selective rule generation can supp ort in teractive data analysis b y providing almost instan tly the resulting rules. With a small application example using frequent closed itemsets instead as the interesting itemsets, w e also illustrated that selective asso ciation rule generation can be useful for significantly reducing the n umber of rules found. 11 lhs rhs supp. conf. 1 {odor=none, gill-size=broad, ring-number=one} => {class=edible} 0.331 1 2 {odor=none, gill-size=broad, veil-type=partial, ring-number=one} => {class=edible} 0.331 1 3 {odor=none, stalk-shape=tapering} => {class=edible} 0.307 1 4 {odor=none, gill-size=broad, stalk-shape=tapering} => {class=edible} 0.307 1 5 {odor=none, stalk-shape=tapering, ring-number=one} => {class=edible} 0.307 1 T able 4: Rules generated from frequent itemsets. lhs rhs supp. conf. 1 {odor=none, gill-size=broad, veil-type=partial, ring-number=one} => {class=edible} 0.331 1 2 {odor=none, gill-attachment=free, gill-size=broad, stalk-shape=tapering, veil-type=partial, veil-color=white, ring-number=one} => {class=edible} 0.307 1 3 {odor=none, gill-size=broad, stalk-surface-below-ring=smooth, veil-type=partial, ring-number=one} => {class=edible} 0.284 1 T able 5: Rules generated from frequent closed itemsets. 12 References Agra wal, R., Imielinski, T. & Swami, A. (1993), Mining asso ciation rules b et w een sets of items in large databases, in ‘Pro ceedings of the 1993 A CM SIGMOD In ternational Conference on Management of Data’, A CM Press, pp. 207–216. Agra wal, R. & Srik ant, R. (1994), F ast algorithms for mining asso ciation rules, in J. B. Bo cca, M. Jarke & C. Zaniolo, eds, ‘Pro c. 20th Int. Conf. V ery Large Data Bases, VLDB’, Morgan Kaufmann, pp. 487–499. Ba yardo, R. J., Agraw al, R. & Gunopulos, D. (2000), ‘Constraint-based rule mining in large, dense databases’, Data Mining and Know le dge Disc overy 4 (2/3), 217–240. Borgelt, C. (2003), Efficient implemen tations of Apriori and Eclat, in ‘FIMI’03: Pro ceedings of the IEEE ICDM W orkshop on F requen t Item- set Mining Implemen tations’. Borgelt, C. (2006), Apriori – Asso ciation Rule Induction , School of Com- puter Science, Otto-v on-Guerick e-Universit y of Magdeburg. URL: http://fuzzy.cs.uni-magdebur g.de/ ∼ b or gelt/apriori.html Borgelt, C. & Kruse, R. (2002), Induction of asso ciation rules: Apriori implemen tation, in ‘Pro ceedings of the 15th Conference on Computa- tional Statistics (Compstat 2002, Berlin, Germany)’, Ph ysik a V erlag, Heidelb erg, Germany . Creigh ton, C. & Hanash, S. (2003), ‘Mining gene expression databases for asso ciation rules’, Bioinformatics 19 (1), 79–86. Go ethals, B. & Zaki, M. J. (2004), ‘Adv ances in frequent itemset min- ing implementations: Rep ort on FIMI’03’, SIGKDD Explor ations 6 (1), 109–117. Hahsler, M., Buc hta, C., Gr ¨ un, B. & Hornik, K. (2007), arules: Mining Asso ciation R ules and F r e quent Itemsets . R pack age v ersion 0.6-0. URL: http://CRAN.R-pr oje ct.or g/ Hipp, J., G ¨ un tzer, U. & Nakhaeizadeh, G. (2000), ‘Algorithms for as- so ciation rule mining — A general survey and comparison’, SIGKDD Explor ations 2 (2), 1–58. Imielinski, T. & Virmani, A. (1998), Association rules... and what’s next? to wards second generation data mining systems, in ‘Pro ceedings of the Second East European Symp osium on Adv ances in Databases and In- formation Systems’, V ol. 1475 of L e ctur e Notes In Computer Scienc e , Springer-V erlag, London, UK, pp. 6–25. Klemettinen, M., Mannila, H., Ronk ainen, P ., T oivonen, H. & V erk amo, A. I. (1994), Finding in teresting rules from large sets of discov ered as- so ciation rules, in N. R. Adam, B. K. Bharga v a & Y. Y esha, eds, ‘Third In ternational Conference on Information and Kno wledge Management (CIKM’94)’, ACM Press, pp. 401–407. 13 Kn uth, D. (1997), The Art of Computer Pr o gr amming, Sorting and Se ar ching , V ol. 3, third edn, chapter Digital Searc hing, pp. 492–512. Koha vi, R. (1996), Scaling up the accuracy of naive-ba y es classifiers: a decision-tree h ybrid, in ‘Pro ceedings of the Second International Con- ference on Kno wledge Disco very and Data Mining’, pp. 202–207. Koha vi, R., Brodley , C., F rasca, B., Mason, L. & Zheng, Z. (2000), ‘KDD- Cup 2000 organizers’ rep ort: Peeling the onion’, SIGKDD Explor ations 2 (2), 86–98. Luo, J. & Bridges, S. (2000), ‘Mining fuzzy asso ciation rules and fuzzy frequency episo des for in trusion detection.’, International Journal of Intel ligent Systems 15 (8), 687–703. Newman, D. J., Hettich, S., Blake, C. L. & Merz, C. J. (1998), UCI R ep ository of Machine Le arning Datab ases , Universit y of California, Irvine, Dept. of Information and Computer Sciences. URL: http://www.ics.uci.e du/ ∼ mle arn/MLR ep ository.html P asquier, N., Bastide, Y., T aouil, R. & Lakhal, L. (1999), Disco vering frequen t closed itemsets for asso ciation rules, in ‘Pro ceeding of the 7th In ternational Conference on Database Theory , Lecture Notes In Com- puter Science (LNCS 1540)’, Springer, pp. 398–416. Piatetsky-Shapiro, G. (1991), Discov ery , analysis, and presen tation of strong rules, in G. Piatetsky-Shapiro & W. J. F ra wley , eds, ‘Knowl- edge Discov ery in Databases’, AAAI/MIT Press, Cam bridge, MA. Srik an t, R., V u, Q. & Agraw al, R. (1997), Mining asso ciation rules with item constraints, in D. Heck erman, H. Mannila, D. Pregib on & R. Uth u- rusam y , eds, ‘Pro c. 3rd Int. Conf. Knowledge Disco very and Data Min- ing, KDD’, AAAI Press, pp. 67–73. Sriv asta v a, J., Co oley , R., Deshpa nde, M. & T an, P .-N. (2000), ‘W eb usage mining: Discov ery and applications of usage patterns from web data’, SIGKDD Explor ations 1 (2), 12–23. T an, P .-N., Kumar, V. & Sriv astav a, J. (2004), ‘Selecting the right ob jec- tiv e measure for asso ciation analysis’, Information Systems 29 (4), 293– 313. Zaki, M. J. (2004), ‘Mining non-redundan t asso ciation rules’, Data Mining and Know le dge Disc overy 9 , 223–248. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment