Pattern Recognition and Memory Mapping using Mirroring Neural Networks
In this paper, we present a new kind of learning implementation to recognize the patterns using the concept of Mirroring Neural Network (MNN) which can extract information from distinct sensory input patterns and perform pattern recognition tasks. It…
Authors: Dasika Ratna Deepthi, K.Eswaran
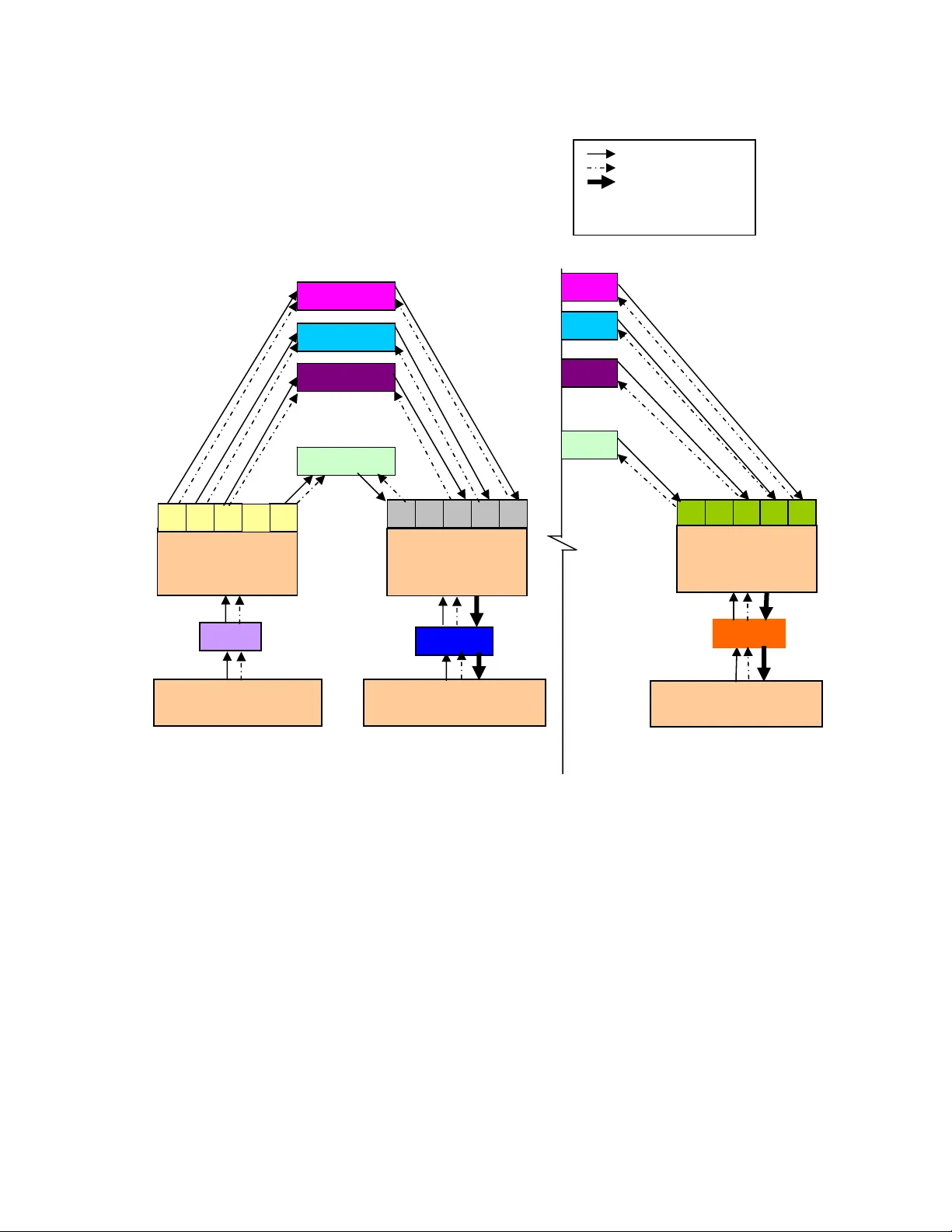
Pattern Recognition and Memory Mapping using Mirroring Neural Networ ks Name(s) Dasika Ratna Deepthi (1) and K. Eswaran (2) Address: (1) Osm ania Univ ersity, Hyder abad - 500 0 07 (2) Sreenidhi Institute o f Science and Technology, Yamnampet, Ghatkesa r, Hyderabad - 501 30, India Email address es radeep07@gm ail.com , kumar.e@gmail.com (Paper #336, accepted in IEEE Internat ional Conf. on Emerging Tre nds in Computing, ICETi C Jan. 2009) Abstract In this pa per, we present a new kind of learni ng implementation to recog nize the patterns u sing the concept of Mirrori ng Neural N etwork (MNN) w hich can extract information from distinct sensory inpu t patterns and perform pa ttern recognition tasks. It is also capabl e of being us ed as an advance d associati ve memory wherein image dat a is associated with voice inputs in an un supervised man ner. Since th e architecture is hierarchical and modul ar it has t he potential of being used to de vise learning engi nes of ever increasing complexity. KEY WORDS Mirrorin g Neural Netw ork, sens ory input p atterns, pattern recognition, associative memory, learning engines. 1: INTR ODUCTION In this paper, we introduce an algorithm using Mirroring Ne ural Networ ks (MNN) w hich perform s a dimensi on reduction of input data fol lowed by mapping, t o recognize pat terns. There have been m any investigations done on pattern reco gnition, a few of which deal with geom etri c feature extraction [1], manifold learn ing [2] and non-lin ear dimensional reduction [3] and [4] etc.,. In addition to pattern recognition thr ough data reduct ion, the neural networ k approach can a lso be used to resol ve high di mensional problems in clustering [5] and to study co mplex neuronal pro perties [6]. We in our app roach, devel op an architect ure which does non-linear data reduction associated wit h mapping using a special typ e of neural network called MNN (refer [7] an d [8] for de tails). The architecture is hierarchical; possesses the ability o f unsupervised learning and in its form is an imitation of th e basic natural neural system [9]. We follow the bottom-up approach that resembles the architecture used by Dileep Georg e and Jeff Hawki ns [10] and [1 1] to recognize the patt erns by orga nizing the MNN modules (a pproxim ating cortical r egions of t he cortical system) of different levels using connections [12]. Our conviction is that the propo sed architecture can be used as a part of an unsupervise d hierarchical learning machine to be use d for complex real-world pattern recogn ition problem , an aspect discusse d in section 3. In this pape r, we deal wit h usage of MN N concept fo r: • Feature extraction of patterns • Mapping the extracted features of the patterns • Construction of the pattern recognition architecture 2: PATTERN RECOGNITI ON AND MEMORY MAPPING We construct a software architecture which does feature extraction coupled with memory mapp ing for a “pattern recognizer”. This architecture is hierarchical and is construc ted out of seve ral modules ea ch of these modules is a “Mirrorin g Neural Netw ork” [7]. T he task of the latter is to take a set of data and then redu ce (compress) the data in suc h a manner t hat informati on is not lost, the compressed data is then passed on to the next m odule. The a dditi onal purpose of the pattern rec ogn iz er is to pe rfo rm au to mat ic memo ry map s, by this we mean: given a set of data which is connected to another set o f data, the pattern recogni zer associates the former set with the latter. For example, suppose we are given a set of data which represe nts the di gitized data (say a .wav file) of the spoken word “ Alice Simmons” and another set of dat a which is a di gitized image of the pe rson, “Alice Simmons”, the n the pattern recognizer can be taught to associate the voiced data to her image. The pattern recognizer can then learn to associate any other speech si gnal containing t he spoken wo rd “Alice Simm ons” to any other im age of “Alice Simmons ”. The type of pattern recognizer described in this example can b e utilized to construct an intelligent device which associates a spoken word to an image . The main characteristics of the architecture are: (i) its input indepen dence (ii) its hierarchical struct ure (iii) its modularity, (being built up of individual modules or “cells”) and (i v) the attribute that each of these modules actually implements a single common algorithm (the MNN algorith m). Since the architecture has these 4 characteristics, it can be easily gene ralized and enlarged to solve a large va riety of problems of increasing complexity and size. The si ngle common algorithm that is used by the MNN which perform a compr ess ion (fe ature extractio n) and a memo ry association of the data, details are below. 2.1. Overview of the pr oposed architect ure In order to design o ur architect ure which has the above mentioned 4 characteristics, we have imitated some features of the neo-corte x [11] in the human brain, which seem to possess these characteristics. The human brain c an encode the data of differe nt sensory input patterns and n ot only recogn ize the patterns but is also able to effectively store these in very efficient memory m aps and is ca pable of sel f-learning an d decision maki ng. Of course , our arc hitecture can at best be said to be a crude copy of the complicated architecture of the neo-corte x whose details are yet unknown and are a s ubject of intense research among neuroscientists. In our approach the hierarc hical architecture is built up of modules co nnected in a tree-like struct ure each module is a MNN, the bottommost level is used to accept the sensory i nput data and extract those features that best capture the pattern s which are to be recognized. At this level, each of the MNN s processes a category of sensory patte rn s. The extracted features of dissim ilar sensory patt erns from the lower level MNNs are used by the upper level MNNs so that th e latter can function as associative m emory maps. That is, in the upper level each MNN maps the extracted features of patt erns belong to a group of sen sory input to the features of the c orrespondi ng pattern group of a different sensory input. (For example, a sensory input representing the spoken word ‘face” is assoc iated with its corresponding visual sensory input i .e., “face image”). This proces s of feature extraction and the associated mapping can be repeated for each of the distinguisha ble sensory patt erns. And we ca n say that our architecture performs a combination of learning and mappin g thus sim ulating the pr ocesses of automatic learning, memorization and recognition as is done by the cortical system. An illustrated pictorial diagram (Figure 1) of the p roposed archit ecture with explanatio n on sampl e implem entation is given below. Let us, for the sake of simplicity, consider only the two categories of sensory input patterns out of N categories (an example case, for the hum an brain the distinct categories of sensory patterns belon g to Sound, Im age, Odor, Taste, Sense/To uch) in our architecture, it will become apparent that there is no loss of generality in choosing only two categories. One of the two input pa tterns is a voice (sound) pattern and the o ther is an image pattern and they may be term ed Category I a nd Cate gory II re spectively (this simplified situation corresponds to N=2, in Fig 1). Furthe r, we assum e th at each of t hese categories contain 3 distinguishable pattern group s in it, say “Face”, “Window” and “Garden” (this c orresponds to k=3, in Fig. 1). Then the bo ttommost level MNNs i.e., MNN I and M NN II are traine d to corresp ondingly extract the best l ow-dimensional fe atures of voice patterns (‘Face’, ‘Window’ and ‘Ga rden’) and image patterns (‘ Face’, ‘Window ’ and ‘Garden ’). These extracted features are c lassified into the 3 distinguishable gr oups by Forgy’s clus tering algorithm [13] and resulting group s are given to the MNNs at the upper level . These up per le vel MNNs are then trained to map the i nput sound to t he correspondi ng image from left to right at Level II. For example if the inpu t data (in a .wav file) is the sound “window” it is automatically associated with the image of a “window”. In this paper the first level of training is supervised in the sense that there is a training session wherein data i s fed in pairs , one contai ning a spoken word and the other an im age. For example, a spoken word “garden” (from a .wav file) is presented to the MNN I along with the imag e of a “garden” (fro m a .bmp file) to MNN II at level I. During the training many such pairs of data (spee ch-cum-im age) belong t o different groups (in o ur exam ple, there are 3 group s) are presented, after t hat both the MNNs, MNN I and MNN II learn to classify the speech and images respectively. At level II these speech data and image data are associat ed by another set of M NNs - one MNN for each group. After successful training, the pattern recognizing architecture will perform as follows: If a word (say a “window”) is sent as inpu t (to MNN I), then the network architectur e will automatically associate this word with the image “window” and the .bmp file containing t hat image is di splayed. Th us the architecture maps speech data to visual data. Level II . . . . . . . . . … … … L e v e l I … … … ……. Sensory Input category I Sensory Input category II Sensory Input cat egory N Figure 1. Illustrated pictorial diag ram of the proposed architecture 2.2. The MN N concept In this parag raph we brie fly describe the functions of the Mirroring Ne ural Network (MNN ), details are given in [7] and [8]. The MNN module is essentially a converging -diverging t ype of art ificial neura l network architecture. The MNN comp resses t he received input and gives an output. The idea is to train the MNN so that the output is as close as po ssible to the input. If this is successful for a particular class of pat terns then the particular MNN has “learnt” the patt ern, the output of the lo west dim ensional hidde n layer be comes the feature set characterizing the pattern. This feature set can then be used to di stinguish i t from ot her patter ns and classify it. So we see an MNN does the following tasks: (i) compresses the input data, (ii) extracts a suitable feature set characterizing t he input pattern and (iii) has the property to re cons truct the o riginal data given the com pressed data. It may be note d, one MNN can be used to recognize either one patt ern or a particular pattern fr om a set of patterns. We use a MNN as a module of our pattern recognition architecture. To summarize this section we can say that we implement the MNN’s feature extraction (at level I) on different ki nds of patterns i.e ., voice samples besides image patterns. In addition to u sual feature extraction, at the upper level, the MNN concept is to carry ou t a Category I Patterns belong to ‘K’ different groups Category II Patterns belong to ‘K’ different groups Category N Patterns belong to ‘K’ different groups Forgy’s algorithm to cluster feature set I (among ‘k’ gr oups) MNN I MNN Ik-IIk MNN II MNN N 1 2 k 3 … k … 1 3 2 MNN I3-II3 MNN I2-II2 MNN I1-II1 k … 1 3 2 Control flow Data flow Control flow along with data -N1 -N2 -N3 -Nk Forgy’s algorithm to cluster feature set II (among ‘k’ gr oups) Forgy’s algorithm to cluster feature set N (among ‘k’ gr oups) memory m ap by connecting two cat egories of sens ory patterns which are associated with eac h other. A nd we construct the architecture fo r pattern recognition with the combination of lower and upper level MNNs which per form dim ensional reduction and memory mapping resp ectively. 2.3. Demonstr ation of the proposed arc hitecture In this section, we describe the procedure followed for training th e pattern recognition network and present the results on an actual example. 2.3.1. Inpu ts to Level I . The inputs to the architecture are pairs of voice sam ples and their corresponding images. The voice samples are the actual spoken words repeate dly uttered by a particular speaker. Actually we took 150 sam ples of the word “face”( i.e., the word “face” repeatedly uttered 150 times) similarly 150 samples of the word “window” and the 150 samples o f the word “ga rden” are taken. Eac h of these words is p aired with a corresponding image data and this data pair is fed to the architectur e as Sensory input I (voi ce) and senso ry input II (image). The procedure to obtain the digitized vo ice samples is as follows: each voice sample is digitized at 2000 samples per second and re-sampled to 51 0 equally spaced poi nts using Ma tlab [14]. These 51 0 values of the word sam ples are considered as representing the sen sory input I (input vecto r of 510 dimensi ons to MNN I). For inputting the data for th e images the procedure is as follo ws: A total of 450 diff erent images were c onsidered in t his study, all the images though different, fall into one of three classes v iz., a face (faces are from the Yale face database [15]), a window or a gar den. Each of these images is resized to a fixed size 17 X 30, contain ing 510 pixels. Th e grayscales (int ensity levels of each pixel ) whose range is from 0 to 255 are rescaled [16] so that they all lie between -1 to +1, these 510 intensity values constitute the input vectors for each sam ple image and are given as input vectors to MNN II. 2.3.2. Cl assificati on at Leve l I. Duri ng the training period when pairs of (voice, image) data are fed to level I, both MNN I a nd MNN II learn (i) to reduce the input data and then (ii) to independently classify their respective inputs. The data redu ction is done f rom 510 to 20 units by using a 3 layer MNN arch itecture, 510-20-510 processing elements. The reduced inputs are then use d to classify the inputs. Fo r example the 20 features extracted by the MNN I cla ssifies its input words, using Forgy’s algorith m into 3 groups (k=3 in figure) for the 3 types of words “face”, “window” and “garden”. Sim ilarly, and M NN II reduces i ts image data to 20 feature s using again a 510 -20-510 architecture and classifies th e input s into 3 groups one for a “face image”, anothe r for “window image” and the third for the “garden im age”. See[7] and [8] for more detail s on data red uction by M NN and its use of Forgy’s algorithm. 2.3.3. Tr aining of MNN’s in Le vel II. In the following example the Level I MNNs are first trained and their inputs classified and then the level II MNN’s are trained for associating words with the corresponding images. But, it is to be mentioned h ere that it is quite possible to e nvisage bot h the levels to be trained simultaneousl y, under the ass umption of simultaneity by using te mporal i nformation [ 10] and [11] . If we assume that the sensory input I is related to Sensory input II, this will happen if the word face is prese nted simultaneously with t he imag e of a face, then MNN I and MNN II can the n classify their inputs and put them in the sam e group (say group 1 for face), simultaneously MNN I1-II1 in Level II will be trained such that t he reduced i nput give n to MNN I 1-II1 (from the MNN I in Level I) is mapped (matched) to the reduced input of MNN II at level I. If this is done properly, then the architectu re will train itself to associate the word face with the image of a face and the word window with the image of a window etc.,. The purpose of Level II is t o associate each group of input from Sensory I to its appropriate group from Sensory II. That is, if th e word “face” is invoked as input, then the architectur e should associate a “face image” to this input. Since there are 3 groups (k=3) in our data, there will be 3 MNNs in Level II each of these have to be t rained wi th the appropriate inputs. We have chosen a 20-20-20 architecture for the 3 MNNs in Level II. The procedure to train these level II MNNs is as follows: the reduced inpu t from MNN I (in this case it is a 20 dimensional vector), becomes the inpu t to the appropriate MNN in Level II . Example, if the i nput (garden word, garden image) is fed as data to level I MNNs then the 20 feature vector (of g arden wo rd) from MNN I is given as input to MNN I3-II3 in Level II so that its out put is eq ual to t he 20 dim ensional feature vector of the garde n-image, obtaine d by data reduction using MNN II in Level I. After the training of the Level II MNNs, the whole architecture can be c onsidered as trained. The functioning of this traine d architecture can be now tested. Simply by inputting a voice sample and finding out if the architecture maps th is voice input to its corresponding imag e and give it as an output. The flow chart of the architectur e is shown in Figure 2. (i) (ii) (iii) (a) (b) (c) Figure 2. Pictorial representation of pattern recognition and memory mapping exe mplified on typical samples from e ach group: (i) w ord ‘face’ mapped to im age ‘face’ (a); (ii) word ‘window ’ mapped to image ‘widow’ (b ); (iii) word ‘garden’ mapped to image ‘garden’ (c). 2.3.4 Results . The experim ent is conducted by using a data set of 450 ( word, image) pai rs, for traini ng purposes 30 0 pairs are use d and then t he remaini ng 150 pairs are used for testing (evalu ation). It is emphasized here that the pairs that were use d for testing the arc hitecture were ne w pairs of data and were NOT used while training th e architecture. Table 1 summarizes our results. At Level I, the efficiencies of the MNN I and MNN II in classifying the voice and image patterns into their appro priate group is found to b e 91.6% and 95.3% respectively (using on ly the reduced input vector of 20 dime nsions). The overall efficiency of recognition, that is, the rate of correct predictio n of a voice input to its appropriate image output is found to be 91.6%. Table 1: Pattern recogni tion and memory mapping using MNN Input to the system Output from the system Success rate of MNN I Success rate of MNN II Over- all effici- ency Voice samples Image samples 91.6% 95.3% 91.6% 3: CONCLUSIONS AND FU TURE WORK We have dem onstrated the success ful functioning of an unsu pervised learning algorithm which has the following feat ures: (i) It is hierarchical and m odular (ii) each module runs on a common algorith m, (iii) capable of automatic data reduction and feature extraction and (iv) pr ovides an efficient associative memory map. Because of th ese features it is capable of being e nlarged a nd used f or more complex lea rning tasks. For example, its ab ility to associate a voice pattern with an image pattern makes it a good candidate fo r devising lear ning machines which can associate memories of two simultaneous events e.g., the image of a train moving with the whistle blowing, the sight of fire with its heat. This kind of learning machine could provid e a method of associat ing memories of t wo different e vents separat ed temporal ly and thus learn t o recognize cause and effect. It is hoped that architecture is flexible enough t o be deployed, in the fut ure, for even more complex pattern recognition tas ks as those perform ed by neo-cortex in the human brain. REFERENCES [1] C. J. C . Burges, Geom etric m ethods for feat ure extraction an d dimensi onal reductio n, In L. R okach and O. Maimon, editors, Data Min ing and Knowledg e Discovery Handb ook: A Complete Guide for Practitioners and Researchers (Kluwer Academic Publishers, 2005). MNN I for feature extraction Forgy’s clustering algorithm Feature set I2 Feature set I1 Feature set I3 MNN I3-II3 MNN I2-II2 MNN I1-II1 Feature set II2 Feature set II1 Feature set II3 MNN II for reconstruction [2] J. Zha ng, S. Z. Li and J. Wang, M anifold learni ng and application s in recognition, In Intelligent Multimedia Processing with Soft Co mputing, Springer-Ve rlag, Heidelberg, 20 04. [3] Hiu Chung Law , Clustering, Dimensionality Reduction an d Side Informati on (Michigan State University, 20 06). [4] G. E. Hinton & R. R. Sala khutdinov, Reducing the Dimensionality of Data with Neural Networks, Science, 313, July 2006, 504-507. [5] Alex L. P. Tay, Jacek M. Zurada , Lai-Pi ng Wong, and Jian Xu , The Hier archic al Fast Learning Artificial Neural Network ( HieFLANN)—An Autonomous Platform for Hierarchic al Neural Network Constructio n, IEEE Transactions on Neural Networks, This article has been accepte d for i nclusion in a future issue of this journal, (200 7). [6] Brian Lau, Garrett B. Stanl ey, Yang Da n, Computati onal subunits of visual co rtical neuro ns revealed by artificia l n eural networks. Proc Natl Acad Sci USA 99(13), 2002, 8974–8979 . [7] Dasika Ratna Deepthi, Sujeet Kuchib holta, K. Eswaran, Dimentionality reductio n and reconstruction using m irroring neu ral networks and object recognition based on reduced dimension characteristic vector, Advances i n Compute r Vision and Inf ormation Technology (ACVIT-07) on Artificial Intelligence , November 200 7. [8] Dasika Ratna Deepthi, G.R. Aditya Krish na, K. Eswaran, automatic pattern classificatio n by unsupervised learning using dimensiona lity reduction of data with mirrori ng neural netwo rks , Advances in Computer Visi on and Infor mation T echnology (ACVIT-07) on Artificial Intelligence , November 2007. [9] Marcus Kaiser, Brain architecture: A design for natural com putation, Roy al Society, 2008, pp 1-13. [10] Dileep George and Jeff Hawkins, A Hierarchical Bayesian Model of Invarian t Pattern Recognition in the Visual Cortex. [11] Jeff Ha wkins an d Dileep Geor ge, Num enta (2007) in Hierarchical Temporal Memory, Conce pts, Theory, an d Termi nology, ( N umenta Inc ), 2007, pp 1- 20 [12] D. C. Van Essen, C. H. Anders on, and D. J. Felleman. Inf ormation pr ocessing in t he primat e visual system: an integrated systems perspective, Science, 255(5043) :419–423, Jan 24 1992. LR: 20041117; JID:0404511; RF: 38 [13] Earl Gose, Richard John sonbaugh & Steve Jost, Pattern recog nition and i mage anal ysis (New Delhi: Prentice Hall of Ind ia, 2000), pp 211-213 [14] http://en.wikipedia.org /wiki/MATLAB [15] http://cvc.yale.edu/projects/yalefaces/yalefaces.html [16] R. C Gonzalez and R. E. Woods, Digital image processing (Englewo od Cliffs, NJ: Prentice-Hall, 2002).
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment