Anonymizing Graphs
Motivated by recently discovered privacy attacks on social networks, we study the problem of anonymizing the underlying graph of interactions in a social network. We call a graph (k,l)-anonymous if for every node in the graph there exist at least k o…
Authors: Tomas Feder, Shubha U. Nabar, Evimaria Terzi
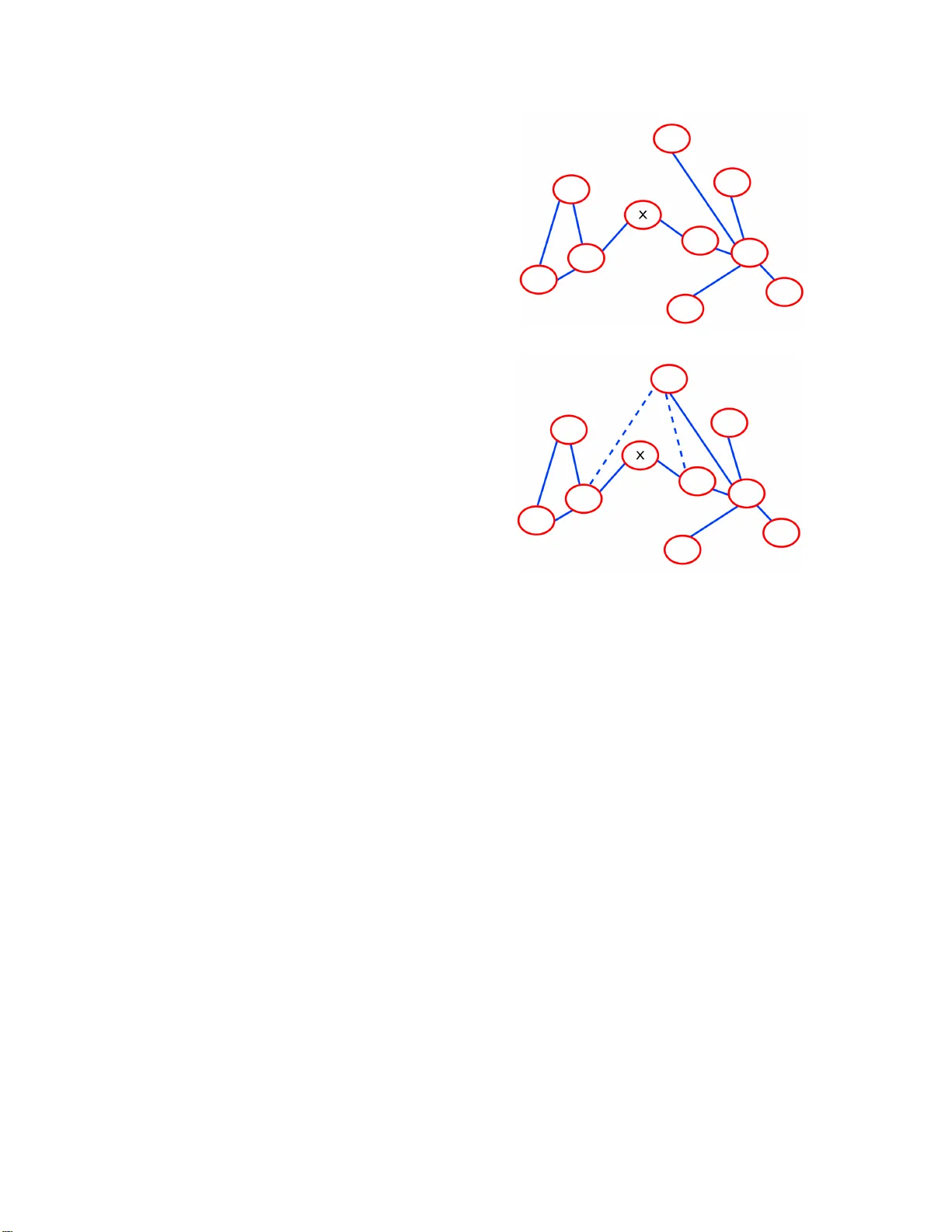
Anon ymizing Graphs T om´ as F eder Stanford Univ ersit y Sh ubha U. Nabar Stanford Univ ersit y Evimaria T erzi IBM Almaden Abstract Motiv a ted b y recent ly disco v ered p riv acy attac ks on so cial net works, w e study the problem of anon ymizing the underlying graph of in terac- tions in a social net w ork. W e call a graph ( k, ℓ ) - anonymous if for ev ery no de in the graph there exist at least k other no des that share at least ℓ of its neigh b ors. W e consider tw o com binatorial problems arising from this notion of anon ymit y in graphs. More sp ecifically , giv en an inpu t graph w e ask for the min im um num b er of edges to b e added so that the graph b ecomes ( k , ℓ ) - anonymous . W e d efi ne t wo v arian ts of this mini- mization problem and study their p rop erties. W e sho w that for certain v alues of k and ℓ the prob- lems are p olynomial-time solv able, wh ile for oth- ers they b ecome NP-hard. App ro ximation algo- rithms for the latter cases are also giv en. 1 In tro d uction The p opularit y of online communities and so cial net works in r ecen t years has m otiv a ted researc h on so cial-net work analysis. T h ough these stud- ies are u s eful in unco v ering the underpin nings of h u man so cial b ehavio r , they also raise priv acy concerns for the individuals inv olv ed. A so cial net w ork is usually rep r esen ted as a graph, where no des corresp ond to individuals and edges capture relationships b et wee n these individuals. F or example, in Link edIn, an on- line net work of professionals, eve ry link b et ween t wo u sers sp ecifies a professional relationship b e- t wee n them. In F a ceb o ok and Ork u t lin k s c or- resp ond to friendsh ip s. There are online com- m u nities that p er m it an y u ser to access the in- formation of eve ry node in the graph an d vie w its neigh b ors. Ho wev er, many communities are increasingly r estricting access to the p ersonal information of other users. F or example, in Link edIn, a user can only see th e p rofiles of h is o wn friends an d their connections. In this pap er, w e consider a scenario where the o wner of a social net w ork w ould lik e to release the underlying graph o f in teractions for so cial- net work analysis pu rp oses, while pr eserving the priv acy o f its users. More sp ecifically , the pri- v ate information to b e protected is the mapping of n o des to r eal-wo rld en tities and in terconnec- tions amongst them. Therefore, w e design an anon ymization framewo rk th at tries to hide th e iden tity of no des b y creating groups of no d es that lo ok similar by vir tu e of sh arin g many of the same n eighb ors . W e call su c h no des anonymize d . Our goal is to anonymize all no d es of the graph b y in tro d ucing minimal changes to the o v erall graph stru cture. In this w a y we can guaran- tee that the anonymize d graph is still usefu l for so cial-net w ork analysis purp oses. Recen tly , Bac kstrom et. al. [4] ha ve sho wn that the most simple graph-anon ymization tec h- nique that remo v es the iden tit y of eac h no de in the graph, replacing it with a random identifi- cation n u m b er instead, is not adequate for pre- serving the priv acy of nodes. Sp ecifically , they sho w that in suc h an anonymize d net w ork, th ere exists an adv er s ary wh o can iden tify target i n- dividuals and the link structure b et ween them. Ho we v er, the problem of designing anonymiza- tion metho ds against such ad versaries is not ad- dressed in [4]. F ollo wing the wo rk of [4], Ha y et. a l. [7] ha ve very r ecen tly giv en a defin ition of graph anon ymity: a graph is k -anon ymous if every no de shares the same neigh b orho o d structure with at least k − 1 other no des. The defin ition is recursiv e, and has some n ice prop erties stu died 1 in [7]. Ho wev er, the fo cus of [7] is mostly on the prop erties of the definitions rather than on algo- rithms to ac h ieve the anonymit y requ iremen ts. Motiv a ted b y [4] and [7], Z hou and P ei [18] consider the follo w ing definition of anon ymity in graphs: a grap h is k -anonymous if for ev ery no de there exist at least k − 1 other no des that share isomorphic 1-neighborh o o ds. T hey consider the problem of minim um graph-mo difi cations (in terms of edge additions) that would lead to a graph satisfying the anonymit y r equiremen t. Although th is d efinition is interesti ng, the al- gorithm presen ted in [18] is not supp orted by theoretical analysis. F ur ther, if the anon ymity definition is extended to consider the n eigh b or- ho o d structure b ey ond ju st the immediate 1- neigh b orho o d of eac h n o de, algorithmic tec h - niques q u ic kly b ecome infeasible. Despite the fact that priv acy concerns in releasing so cial-net w ork d ata ha ve b een pin- p oin ted, there is no agreement on the defin ition of p riv acy or anonymit y that should b e used for suc h data. In this pap er, we try to mo v e this line of researc h one step f orward by prop osing a new d efinition of graph anon ymity that is inlin e to a certain extent with the d efinitions provided in [7]. Ou r definition of anonymit y is in a sens e less strict than the one p rop osed in [1 8 ]. How- ev er, w e consider it to b e natural, intuitiv e and more amenable to theoretical analysis. In tuitiv ely our definition aims to p rotect an individual f r om an adversary who kno ws some subset of the individu al’s neighbors in the graph. After anon ym izatio n, th e h op e is that the ad- v ersary can no longer identi fy the target indi- vidual b ecause sev eral other n o d es in the graph will also share this subset o f neigh b ors . F urther, during anonymizat ion, the ident ifying sub set of neigh b ors thems elves will b ecome distorted and harder for the adv ersary to iden tify . The Problem: W e define a graph to b e ( k , ℓ )- anon ymou s if for ev er y node u in th e graph there exist a t least k other no d es that share at le ast ℓ of their neighbors with u . In order to m eet this anonymit y requiremen t one could trans f orm an y graph into a complete graph. F or a graph consisting of n n o des this would mean that ev ery no de w ould share n − 2 n eigh b ors with eac h of the n − 1 other no d es. Although suc h an anon y m iza- tion wo u ld preserve priv acy , it w ould mak e th e anon ymized graph u s eless for an y study . F or this r eason we imp ose the additional r equ iremen t that th e minimum num b er of su c h edge add itions should be made. The aim is to preserve the util- it y of the original graph, while at the same time satisfying th e ( k , ℓ )-anon y m it y constrain t. Giv en k and ℓ w e formally d efine tw o v ari- an ts of the gr aph-ano nymization pr ob lem th at ask f or th e min im um num b er of edge add itions to b e made so that the resulting graph is ( k , ℓ )- anon ymou s . W e sh o w that for certain v alues of k and ℓ th e p roblems are p olynomial-time solv- able, wh ile for others they are NP-hard. W e also present simple and int uitiv e a ppro ximation algo- rithms for these h ard instances. T o su mmarize our con tr ib utions: • W e p rop ose a n ew definition of graph anon ymity building on previously p rop osed definitions. • W e pro vide the first form al algorithmic treat- men t of the graph -anonymizati on problem. Besides graph anonymizatio n , the com b inato- rial problems w e study here ma y also arise in other domains, e.g., graph reliabilit y . W e there- fore b eliev e that the problem defi n itions and al- gorithms w e presen t are of indep endent in terest. Roadmap: The rest of the pap er is organized as follo ws. In Section 2 we s ummarize th e related w ork. Section 3 giv es the necessary notation and d efi nitions. Algorithms and hardness results for different instances of the ( k , ℓ )-anon ymization problem are giv en in Sections 4, 5, 6 and 7. W e conclude in Section 8 . 2 Rela ted W ork As mentio ned in the Introd uction, there has b een some p rior work on priv acy-preserving releases of so cial-net w ork graphs. The authors in [4] sh o w that the n aiv e approac h of simply masking user- names is not su ffi cien t anon ym izatio n. In par- ticular, th ey show that, if an adversary is given the chance to create as few as Θ(log( n )) new ac- coun ts in the net work, p rior to its release, then 2 he can efficiently r eco v er the s tructure of con- nections b et ween an y Θ (log 2 ( n )) no des c hosen apriori. He can do so b y identi fying the n ew ac- coun ts that he inserted in to the netw ork. Th e fo cus of [4] is on r evea ling th e p o wer of suc h ad- v ersaries and not on devising metho d s to pr otect against them. In [7] the authors exp er im entally ev aluate h o w m u c h bac kgroun d inform ation ab out the neigh- b orho o d of an ind ividual w ould b e sufficien t for an adv ers ary to u n iquely id en tify that individ u al in a naivel y anon ymized graph. Additionally , a new recursive defin ition of graph anon ym it y is give n. The definition sa ys that a graph is k -anon ymous if f or eve ry structure query there exist k no des that satisfy it. The d efinition is constru cted f or a certain class of structure queries that quer y the neighborh o o d s tr ucture of the no des. Ou r d efinition of anon ymity is in- spired b y [7], ho wev er it is subs tan tially different. Moreo v er, the fo cus of our wo rk is on the com- binatorial p roblems arisin g fr om our anon ymity definition. V ery recen tly , the authors of [18] consid er yet another defin ition of graph anonymit y; a graph is k -anonymo us if for ev ery no de there exi st at least k − 1 other no des that share isomorph ic 1- neigh b orho o ds. Th is definition of anonymit y in graphs is d ifferen t from our s . In a sense it is a more str ict one. Moreo v er, though the algorithm present ed in [18] seems to work we ll in pr actice, no theoretical analysis of its p erformance is pre- sen ted. Finally , extending the priv acy definition to more th an j ust the 1-neighborh o o d of no d es causes the algorithms of [18] to qu ic kly b ecome infeasible. The problem of protecting sensitive link s be- t wee n individuals in an anon ymized so cial net- w ork is considered in [17]. Simple edge-deletion and n o d e-merging algorithms are p rop osed to r e- duce the risk of sensitiv e link disclosure. This w ork is different from ours in that we are pri- marily in terested in protecting the ident it y of the individuals while in [17] the emphasis is on pro- tecting the types of links asso ciated with individ- uals. Also, the combinatorial problems that we need to solv e in our framework are very different from the set of pr ob lems discussed in [17]. In [6] th e authors stu dy the pr oblem of as- sem b lin g pieces of a graph o w ned by different parties pr iv ately . They prop ose a set of cryp to- graphic proto cols th at allo w a group of auth or- ities to join tly reconstruct a graph without re- v ealing the id en tit y o f the no des. The graph thus constructed is isomorphic to a p erturb ed version of the original graph. The p erturb ation consists of addition and or deletion of no des and or edges. Unlik e that work, we try to anonymize a single graph by mo difyin g it as little as p ossib le. More- o ve r, our metho d s are purely com binatorial and no cryptographic proto cols are inv olv ed. Korolo v a et. al. [8 ] in v estigate an attac k where an adversary strategically subv erts user accoun ts. He th en u ses the online int erface pro- vided by the so cial n et wo rk to gain access to lo- cal neighborh o o ds and to piece th em together to form a global picture. The auth ors pr o vide rec- ommendations on wh at the lo ok ahead of a so cial net work should b e to r ender su c h attac ks infeasi- ble. This work do es not consider an a non ymized release of the en tire net wo r k graph and is th us differen t from ours. Besides graphs , there h as b een considerable prior work on anon ymizing traditional relat ional data s ets. The line of work on k -anonymit y found in [1, 11, 9, 12, 14, 10] aims to minimally suppr ess or generalize public attributes of indi- viduals in a dat abase in su c h a wa y that every individual (identifiable by his public attributes) is hidd en in a group of size at least k . Our notion of graph anonymit y d ra ws inspir ation from this. Apart f rom suppr ession or generalizat ion tec h- niques, p erturbation t ec hniqu es ha v e also b een used to anonymize relational data sets in [2, 3, 5]. P erturb ation-based approac hes for graph anon ymization are also considered in [ 7, 16]; in that ca se edges are randomly inserted o r delet ed to anonymize the graph. W e do not consider p erturb ation-based approac hes in th is pap er . 3 Preliminari es In this section we formalize our definition of graph anonymit y and in tro d uce tw o n atural op- timizatio n prob lems that arise from it. Throughout the pap er w e assume th at the 3 so cial-net w ork graph is simple, i.e. , it is u n di- rected, u nw eigh ted, and con tains n o self-loops or m u lti-edges. This is an imp ortan t category of graphs to study; most of the aforemen tioned so- cial net w orks (F ace b o ok, Linke dIn, Orkut) allo w only bid irectional links and are thus instances of such simple graph s . W e assu me that the ac- tual ident ifiers of ind ivid ual no des are remov ed prior to fu rther anon ymization. Our definition for graph anonymit y is inspired by the notion of k -anon ym it y for r elational data w herein eac h p erson, iden tifiab le by his p ublic attributes, is required to b e hid den in a group of size k . In the case of a so cial-net w ork graph, the pub licly- kno wn attributes of a user would b e (a s u bset of ) his connections (and in terconnections amongst them) within the graph. Consider a simple unlab elled graph and an ad- v ersary who knows th at a target ind ividual and some num b er of h is friend s form a clique. In the released graph, the adv ersary could lo ok for suc h cliques to narro w d o wn the set of no d es that migh t corresp ond to the target individual. The goal of an anon ymization sc h eme is to preven t suc h an adv er s ary f rom uniquely id entifying the individual and his remaining connections in the anon ymized graph. W e ac h iev e this b y in tro ducing an anonymit y prop erty that requir es that for ev ery no de in the graph, some sub set of its n eighb ors should b e shared by other n o d es. In this wa y , an adv ersary who knows some subset of the neigh b ors of a tar- get in dividual and can ev en pinp oin t them in th e graph, will not b e able to d istinguish the target individual from other no d es in the net w ork that share this sub set of n eigh b ors . F urther, in the pro cess of anonymiz ation, th e iden tifying subset of neighbors itself b ecomes distorted and hard er for the adv ersary to p inp oint . More formally we define the ( k , ℓ )-anon ymit y prop erty as f ollo ws. Definition 1 (( k , ℓ )-anon ymity) . A gr aph G = ( V , E ) is ( k , ℓ )-anonymous if for e ach vertex v ∈ V , ther e exists a set of vertic es U ⊆ V not c on- taining v such that | U | ≥ k and for e ach u ∈ U the vertic es u and v shar e at le ast ℓ neighb ors. Example 1. A clique of n no des is ( n − 1 , n − 2) - anonymous. (a) Inp ut graph G (b) (4,1)-anonymous transformation of G Figure 1: In Figur e 1(a) an adversary can iden- tify Alice as the no de marke d X. Figure 1(b) is a (4,1)-anon ymous transformation of the grap h . T o demons trate the kinds of attac ks w e hop e to pr otect against, w e giv e another example. Example 2. Consider the gr aph in Figur e 1(a). Supp ose an adversary knows that Alic e is in this gr aph a nd th at A lic e i s c onne cte d to a friend who is p art of a triangle. Ther e is only one suc h no de in the gr aph and henc e the adversary wil l b e able to determine that the no de marke d X in the gr aph uniquely c orr esp onds to Alic e. F r om this he may b e able to fu rther infer the identities of Alic e’s neighb ors and their neighb ors as wel l. Now if the e dges shown in dotte d lines i n Figur e 1(b) a r e adde d to this gr aph, the r esulting gr aph is (4 , 1) - anonymous. In this new gr aph, A lic e is no longer the only no de c onne cte d to a no de of a triangle. F urther, ther e is no longer only one triangle in the gr aph. Giv en an input graph G = ( V , E ) with n no des, and in tegers k and ℓ , our goal is thus 4 y Clique of size k x (a) Input graph G u Clique of size k x y (b) W eakly ( k − 1 , 1) - anonymized graph G ′ Figure 2: Illustrativ e examp le of the difference b et ween we ak and str ong anon y m it y . to transf orm the graph int o a ( k , ℓ )-anonymous graph. W e fo cus on transformations that al- lo w only additions of edges to the original graph In order for the anon ym ized graph to remain useful f or so cial-net work (or other) studies, w e need to ensur e that the tran s formed graph is as close as p ossib le to the original graph. W e ac hiev e this b y requir ing that a m inim u m num- b er of edges should b e added to G so th at the ( k , ℓ )-anon ymity prop ert y holds. Th is leads us to the f ollo wing tw o v arian ts of the ( k , ℓ )- anon ymization pr ob lem. Problem 1 (W eak ( k , ℓ )-anon ym ization) . Given a gr aph G = ( V , E ) and inte gers k and ℓ , find the minimum numb er of e dges that ne e d to b e adde d to E , to obtain a gr ap h G ′ = ( V , E ′ ) that is ( k , ℓ ) - anonymous. The follo wing example illustrates the w eak- anon ymization pr ob lem. Example 3. Consider the input g r ap h G of Fig- ur e 2(a). The gr aph c onsists of a clique of size k and 2 no des x and y c onne cte d by an e dge. The no des in the cliqu e ar e al l ( k − 1 , k − 2) - anonymous. H owever, the existenc e of x and y pr events G fr om b eing ful ly ( k − 1 , 1) -anonymous. Assume now that we c onne ct b oth x and y to a single no de u of the clique. In this way, we c onstruct gr aph G ′ shown in Figur e 2(b) . Obv i - ously, G ′ is ( k − 1 , 1) -anonymo us; al l the no des in G ′ (including x and y ) have k − 1 other no des that shar e at le ast one of their neighb ors. F or x and y , this neighb or is no de u . The p roblem in the ab o ve example is that graph G ′ satisfies the ( k − 1 , 1)-anon ym it y re- quirement , how ev er, the anonymit y of n o des x and y is ac hiev ed via n o de u that wa s n ot a part of their initial set of neighbors in G . Thus, the goal of h aving many other n o d es sharing the original neighborh o o d stru cture of x or y is not necessarily ac hiev ed unless we p lace ad- ditional requirements on the anonymizati on pro- cedure. T o this end w e in tro d u ce the pr oblem of str ong anonymization . Strong anon ymity places additional restrictio ns on ho w anon ymit y can be ac hiev ed and pr o vides b etter p riv acy . Definition 2 (Str on g ( k, ℓ )-transform ation) . Consider gr aphs G = ( V , E ) and G ′ = ( V , E ′ ) , so that E ⊆ E ′ and G ′ is ( k , ℓ ) - anonymo us. F or fixe d k and ℓ , we say that G ′ is a strongly- anon ymized transformation of G , if f or eve ry vertex v ∈ V , ther e exists a set of vertic es U ⊆ V not c ontaining v such that | U | ≥ k and for e ach u ∈ U , | N G ( v ) ∩ N G ′ ( u ) | ≥ ℓ . Her e N G ( v ) is the set of neighb ors of v i n G , and N G ′ ( u ) is the set of neighb ors of u i n G ′ . Therefore, if a graph G ′ is a strong ( k , ℓ )- transformation of graph G , th en eac h v ertex in G ′ is required to h a v e k other vertice s sharing at least ℓ of its original neigh b ors in G . F or this to b e p ossible, ev ery v ertex must ha ve at least ℓ neigh b ors in the original graph G to b egin with. Example 4. Consider again the gr aph G of Figur e 2(a) and its tr ansformation to gr aph G ′ shown in Figur e 2(b). In Example 3 we showe d that gr aph G ′ is ( k − 1 , 1) -anonymous in the we ak sense. However, i n or der to get a str ong ( k − 1 , 1) -tr ansformation of G , we would have to c onne ct e ach of the no des x and y to k − 1 other no des fr om the clique. The defin ition of a strong ( k , ℓ )-transformation giv es rise to t he follo wing str ong ( k , ℓ ) - anonymizatio n p r oblem. Problem 2 (Strong ( k , ℓ )-anonymiza tion) . Given a gr aph G = ( V , E ) and inte gers k and ℓ , find the minimum numb er of e dges that ne e d to b e adde d to E , to obtain gr aph G ′ = ( V , E ′ ) that is a str ong ( k , ℓ ) - tr ansfo rmation of G . 5 Ob viously ac h ieving s trong anonymit y wo uld require th e addition of a larger num b er of edges than w eak anon ymity . Th is s tatement is formal- ized as follo ws. Prop osition 1. Consider input gr aph G = ( V , E ) and inte gers k and ℓ . L et G ′ = ( V , E ′ ) b e the ( k , ℓ ) -anonymous gr aph that is the opti- mal solution for Pr oblem 1, and G ′′ = ( V , E ′′ ) b e the ( k , ℓ ) -anonymous gr aph that is the opti- mal solution for Pr oblem 2. Then it holds that | E ′′ | ≥ | E ′ | . The notion of ( k , ℓ )-anon ymity is strongly re- lated to th e immediate neighbors of a n o de in the graph, and ho w these are shared with other no des. Th er efore, for eve ry no de u it is imp or- tan t to know the n o d es that are reac hable from u via a path of length exactly 2. Giv en its imp or- tance, w e define the n otion o f 2-neigh b orho o d of a n o de as f ollo ws. Definition 3 (2-neigh b orho o d) . Given a g r aph G = ( V , E ) and a no de v ∈ V we define the 2 - neighb orho o d of v to b e the set of al l no des in G that ar e r e achable fr om v via p aths of length exactly 2 . W e also defin e tw o more terms that will b e used in the r est of the p ap er. Definition 4 (Residu al Anonymit y) . Consider a gr aph G = ( V , E ) that we would like to make ( k , ℓ ) -anonymous. Consider any no de v ∈ V and supp ose that k ′ other no des in the gr aph shar e at le ast ℓ of v ’ s neighb ors. Then, we define the r esidual anonymity of v to b e r ( v ) = m ax { k − k ′ , 0 } . The r esidual anonymity of a gr aph G = ( V , E ) is define d to b e r ( G ) = P v ∈ V r ( v ) . W e d efine the concept of a deficient no de f or no des that are n ot ( k , ℓ )-anonymous. Definition 5 (Deficien t No de) . A no de v is de- ficient if r ( v ) > 0 . It is the deficient no des th at w e n eed to tak e care of in order to anon ymize a graph. With these definitions in hand , we are now ready to pro ceed to the tec hnical results of the pap er. 4 (2 , 1) - anon ymization In this section we provide p olynomial-time algorithms for the weak and strong (2 , 1)- anon ymization problems. First, it is easy to see that th ere is a simp le c haracterization of (2 , 1)- anon ymou s graph s. T his fact is captured in the follo wing prop osition. Prop osition 2. A gr aph G = ( V , E ) is (2 , 1) - anonymous if and only if e ach vertex u ∈ V is (a) p art of a triangle, (b) adjac ent to a vertex of de gr e e at le ast 3, or (c ) is the midd le vertex in a p ath of 5 vertic es. The main idea of the algorithms th at w e de- v elop f or (2 , 1)-anon ym izatio n is that th ey add the minimum n u m b er of ed ges so th at ev ery ver- tex of the resulting graph satisfies one of th e con- ditions of Prop osition 2 . Bo th algorithms pro- ceed in t wo p h ases: the deficit- assignment and the deficit-matching p hase. The d efi cit assign- men t r equires a linear scan of the graph in which deficits are assigned to vertices. Rough ly sp eak- ing, a deficit of 1 signifi es that the v ertex needs to b e conn ected to an other v ertex of non-zero deficit by the addition of an extra edge. This added edge ensu res that the (2 , 1)-anon y m it y r e- quirement f or the vertex or its neighb ors will b e satisfied. On ce the deficits are assigned to ver- tices the algorithms pr o ceed to the actual addi- tion of edges. T he edges are added by taking into accoun t the deficits of all vertic es. F or example, t wo v ertices b oth of deficit 1 can b e connected b y the add ition of a s ingle edge (if they are not already neighbors and are not isolated). In this w ay , a single edge accommo dates a total deficit of 2. T he min im um num b er of edges to b e added can b e foun d via a matc hing of the v ertices with deficits. The matc hing consists of edges that are not already in the graph. A p erfect matc h ing is the m atc hing that satisfies all the deficits. In the case of we ak anon ym izatio n, this matc h ing can b e found in linear time by r andomly p airing up non-adjacen t v ertices with deficits. F or strong anon ymization, it needs to b e explicitly com- puted b y s olving the maxim um -matc hing prob- lem o v er edges th at are not already in t he graph. Another k ey p oin t in the dev elopment of our algorithms is that in order to assign deficits it 6 suffices to explore only vertice s that are w ith in a distance 4 from some leaf v ertex or from a verte x of d egree 2. Any other vertex can b e sh o wn to satisfy the cond itions of Prop osition 2. Finally , it only requir es a case analysis to sh o w that our algorithms optimally assign deficits to ve rtices, indep end en tly of th e ord er in whic h they tra verse the vertice s of the inp ut graph durin g the fi rst phase. F or lac k of space w e only giv e a sket c h of the algo rithms and pro ofs in this section. 4.1 Linear-time w eak (2 , 1) -anon ymi- zation As we h a ve already mentio ned our algorithm for the w eak (2 , 1)-anon ym izatio n pr ob lem has t wo phases (1) deficit assignment and (2) deficit matc hing 1 Deficit Assignmen t: First assume that the input graph has no isolated v ertices – we will sho w ho w to deal with isolated vertice s later. F or the deficit-assignmen t phase, the algorithm starts with an unmarke d ve r tex of degree 1 or 2 and explores ve rtices within a distance 4 of it. Deficits are assigned as f ollo ws: • F or an isolated edge uv , w e assign deficit 1 to u and d eficit 1 to v ; it ma y b e that b oth edges w ill b e add ed at u . • F or an isolated path uv w , w e assign d eficit 1 to v . • F or an isolated p ath uv w x , w e assign deficit 1 to v and deficit 1 to w . • F or a su b graph consisting of a path uv w with adjacent ve rtices attac hed to w , we as- sign deficit 1 to v . • F or a comp onent uv X i with v ertex u ha v in g degree one with v ertex v connected to a set of vertice s X i suc h that eac h x ∈ X i has de- gree 1 (and no other v ertices) assign deficit 1 to v . This comp onent corresp ond s to an isolated s tar cen tered at v . 1 Recall that a no d e u is assigned deficit i if i edges need to b e added b etw een other non-zero deficit vertices and u in order to satisfy th e anon ymity req uirements of u or u ’s n eigh b ors. • F or a comp onent consisting of a s q u are uv w x (isolated square), we assign deficit 1 to u and deficit 1 to w ; it ma y b e that the t wo edges will b e added at u and v , or that u and w w ill b e joined. • F or a su b graph consisting of a square uvw x with edges (one or more) ux i coming out of the square, we assign d eficit 1 to v . • F or a subgraph consisting of s quares uv 1 wx 1 , uv 2 wx 2 , . . . , uv j wx j , we assign deficit 1 to one of the v i ’s. • Finally , for a su bgraph consisting of a v ertex u adjacen t to v ertices x i of d egree 1 and to a vertex y of degree 2, assign d eficit 1 to y . All the v ertices that are visited in this process are marke d (that is the assigned d eficits cov er all m ark ed ve rtices) and the defi cit-assig nment pro cess rep eats s tarting with the next unmark ed v ertex until no more u n mark ed v ertices of degree 1 or 2 remain. Deficit Matching: If the num b er of ve rtices with deficit 1 is 2 m , and 2 m ≥ 4 or 2 m = 2 – in some case other th an an isolated edge uv – then , w e need to fi nd an y p erfect matc h ing amongst these vertice s to fin d the edges to add. The matc h ing of deficits can b e d one in linear time sin ce an y (random) pairing o f non-adjace n t v ertices with non-zero deficits suffices. In this case we add m extra ed ges. If the num b er of v ertices with deficit 1 is 2 m + 1, then all but one of these v ertices can b e matc h ed, and a single edge needs to b e added to the remaining vertex, connecting it to some v ertex of d egree at least 2. This results in a total of m + 1 extra edges. There are, how ev er, s ome sp ecial cases th at we need to tak e care of firs t. Sp ecial Cases: Before find ing the p erfect matc hing we matc h all isolated edges to eac h other. Th is is b ecause the isolated edges need to b e connected in a sp ecial wa y to tak e care of the deficits at th e tw o end s. F or a pair of isolated edges uv and u ′ v ′ , we add the edges uu ′ and v u ′ (w e treat the t wo defi cits of 1 at u and v as b eing concen trated at u ). In the end we ma y b e left with a single isolated edge uv . In this case, t wo 7 edges need to b e added and w e can connect them to an y other v ertex in the graph forming a trian- gle. Similarly , in the case where the remainder is an isolated s tar cen tered at v with vertice s x i of degree one, it is en ou gh to add a s ingle edge to connect v ertices x j and x j ′ of th e star. Isolated V ertices: It remains to tak e care of isolated v ertices. F or this we consider a set of s ix isolated ve rtices u, v , w , u ′ , v ′ , w ′ and we connect them with edges uv , uw , uu ′ , u ′ v ′ , u ′ w ′ . T h ese fiv e edges can tak e care of the six isolated ve r - tices. In general, the ve rtices with deficit 1 can b e attac h ed to isolated vertices fi r st, w ith tw o ex- ceptions to b e considered next. When w e ha ve an isolated edge xy , one of the t wo defi cits of 1 can b e satisfied by connecting x to an isolated v ertex, but the other one can also b e satisfied b y connecting x to an isolated ve rtex u if u is also made adjacent to t w o other isolated vertic es v and w to obtain the ab o ve men tioned comp o- nen t. Similarly if x is only adjacen t to ve r tices y i of d egree 1, then the d eficit 1 at x can only b e matc hed to an isolated u if u is also m ad e adja- cen t to t w o other isolated v ertices v and w . In the en d w e will b e left with fewer than six iso- lated v er tices which eac h need one edge. Th ese can b e connected to an y vertex in the graph of degree at least 2. The optimalit y follo ws because a tree on 5 ve rtices is optimal sa vin g. Theorem 1. The ab ove algorithm solves opti- mal ly the we ak (2 , 1) -anonymization pr oblem in line ar time. Pr o of Sketch: It requires a case analysis (that w e omit for lac k of sp ace) to s ho w that the deficit-assignmen t scheme we describ ed ab o ve is complete and optimal and that the total defi cit assigned is in dep endent of th e order in whic h the v ertices of the graph are tra v ersed. Sin ce we fi nd a p erfect matc hin g, w e satisfy these deficits with as few edges as p ossible, hen ce, the optimalit y of the algo rithm. It is also easy to see that the deficit-assignmen t tak es time linear with resp ect to the num b er of edges in the graph : fi rst we only consider ve rtices of degree one or tw o as starting p oin ts. F or ev ery suc h v ertex we only h a ve to explore all v ertices within a distance 4. Th is is b ecause an y other v ertex can b e seen to satisfy one of the condi- tions of Prop osition 2. Af ter eac h iteration of the deficit assignmen t, we mark all the vertices that ha ve b een visited in this pro cess as marked (that is t he assigned deficits co v er all visited v ertices). The deficit-assignment pro cess con tinues s tart- ing with the n ext un mark ed vertex of d egree 1 or 2. Th e scannin g of the algorithm requ ires on ly linear time with resp ect to the num b er of edges in the graph since ev ery tra versed edge connects only mark ed endp oin ts and thus n o edge n eeds to b e trav ersed more than once b y the algorithm. The deficit-matc hing phase is also linear since it only requires to find any (rand om) matc h ing b et ween non-adjacent deficits. 4.2 P olynomial-time strong (2 , 1) - anon ymization The algo rithm for solving the strong (2 , 1)- anon ymization p roblem is v ery s im ilar to the one presented in the previous section, so we only briefly d iscuss it here. F o r brevit y w e av oid men- tioning v arious sp ecial cases that are similar to the w eak-anon ymization p roblem. Th e first key difference is that f or strong (2 , 1)-anon ymization w e need to dev elop a different deficit-assignmen t sc heme. Although the actual structures w e ha ve to consider for assigning the deficits are the s ame w e need to assign different deficits to different v ertices so th at we satisfy the strong anonymit y requirement . This is b ecause an ed ge added at a vertex with assigned deficit can only help the original neigh b ors of the v ertex, and not the v er- tex itself. The second difference is that in the deficit-matc hing p hase w e n eed to actual ly solv e a maxim um -matc hing p roblem; not eve ry r an- dom pairing of non-adjacen t v ertices with as- signed defi cit is a v alid solution. In strong (2 , 1)-anon ymization we first ha ve to assume that there are no isolated ve rtices in the input graph G ; otherw ise strong (2 , 1)- anon ymity is n ot ac hiev able f or th ese v ertices. Deficit Assignmen t: F or th e deficit- assignmen t step, the algorithm s tarts with an unmarked vertex in the input graph with degree 1 or 2 and assigns deficits as follo ws: • F or an isolated edge uv , assign deficit of 2 8 at eac h end . • F or an isolated path uv wx , put deficit 1 at v and at w . • F or an isolated sq u are uv w x , put deficit 1 at u and v . • If such a squ are has edges already coming out of v , put j ust deficit 1 at u . • If multi ple squares uv i wx i all start fr om ver- tex u , then assign deficit 1 to one of the v i ’s. • F or a path uv w , put deficit 1 at eac h of the 3 vertice s. • F or a v ertex of d egree at least 3 attac hed to v ertices of degree 1, p ut tw o deficits of 1 at degree 1 v ertices. • If a path starts uv w x , with x of degree at least 2, put d eficit 1 at v and 1 at w . • If in addition w h as other edges coming out of it, put d eficit 1 just at v . Otherw ise if in addition only v h as other edges coming out of it that join to a v ertex of degree 1, put deficit 1 just at w . All vertice s that are visited in the pro cess are mark ed, and th e algorithm p ro ceeds w ith the next unmarked ve rtex until th ere are no un- mark ed v er tices left. Deficit Matc hing: F or solving the strong (2 , 1) - anonymizat ion pr oblem exactly we n eed to solv e a maxim um-matc h ing problem b et we en the no des with deficits. This can b e done in p olyno- mial time ([13 ]). Note, that in th e weak (2 , 1)- anon ymization problem any random p airing of non-adjacen t no d es with d eficits was sufficien t, allo wing for a linear-time matc hing p hase. This w as b ecause with the exception of isolated edges and isola ted paths of length 4, there w as no c ase in whic h tw o v ertices of non-zero deficit could b e adjacen t. This is not the case in the strong anon ymization pr oblem, and h ere a maxim u m- matc hing problem n eeds to b e solv ed ov er ed ges that are not already in the graph . A linear-time deficit-matc hing algorithm with a small additiv e error can also b e d evelo p ed. This is summarized in the follo wing theorem. Theorem 2. The str ong (2 , 1) -anonymization pr oblem c an b e ap pr oximate d in line ar time within an additive err or of 2, and c an b e solve d exactly in p olynomial time. Pr o of Sketch: It requires again a case analy- sis to show that the deficit-assignment s cheme is optimal and indep enden t of the order in which w e tra ve rse the v ertices. No w, if all deficits add up to m , they can easily b e p aired using a greedy linear-time matc hing al- gorithm. Ho w ever, the last 2 deficits may b e as- signed to adjacen t ve rtices. S o instead of adding ⌈ m/ 2 ⌉ edges, w e ma y add ⌈ m/ 2 ⌉ + 2, for an ad- ditiv e error of 2. If instead we use a m axim um- matc hing a lgorithm to matc h as many defi cits as p ossible and satisfy the unm atc hed deficits ind i- vidually , the problem can b e solv ed optimally in p olynomial time. 5 F rom (6 , 1) to (7 , 1) - anon ymit y W e sho w here th at give n a graph that is al- ready (6,1)-anon ymou s , it is NP-hard to fi nd the minimal num b er of edges that need to b e added to make it either weakl y o r strongly (7 ,1)- anon ymou s . Th is r esu lt pro vides in s igh t into the complexit y of the anon ymization problem, show- ing that it is hard to ac hiev e anonymit y ev en incremen tally . The result follo w s from a reduc- tion from th e 1-in- 3 satisfiability problem. An instance of 1-in-3 s atisfiability consists of triples of Bo olean v ariables ( x, y , z ) to b e assigned v al- ues 0 or 1 in suc h a w a y that eac h triple con tains one 1 and tw o 0s. T h is problem wa s shown to b e NP-complete by Sc h aefer [15]. W e first show that ev en a restricted f orm of the 1-in-3 satisfia- bilit y problem is NP-complete. Lemma 1. The 1-i n-3 satisfiability pr oblem is NP-c omplete e ven i f e ach variable o c curs in ex- actly 3 triples, no two triples shar e mor e than one variable, and the total numb er of triples is even. Pr o of. W e pro v e this b y taking an arbitrary in - stance of the 1-in-3 satisfiabilit y p roblem and con ve rting it to an instance satisfying the con- strain ts of the ab ov e lemma. W e start off by renaming m ultiple occur rences of a v ariable x as 9 x 1 , x 2 , and so on , so that b y the end, eac h v ari- able o ccurs in at most 1 triple and no t wo triples share more than one v ariable. W e can then en- force the condition that eac h x i b e equal to x i +1 b y inserting the tr ip les ( x i , u, v ), ( x i +1 , u ′ , v ′ ), ( u, u ′ , w ) and ( v , v ′ , w ). This guaran tees at most 3 o ccurr ences of eac h v ariable in triples. If a v ariable y o ccurs in 2 triples, w e ma y include a triple ( y , z , t ) in tr o ducing tw o n ew v ariables, so that at the end of this pro cess eac h v ariable o c- curs in either 1 or 3 tr iples. Finally we mak e nine copies of the entire instance, eac h lab eled ( i, j ) with 1 ≤ i, j ≤ 3, and equate the z s that ha ve the same i a nd also equate the t s that hav e the same j . Th is guaran tees th at eac h v ariable app ears in exactly 3 triples. Making tw o copies of this instance guaran tees that the num b er of triples is ev en . Theorem 3. Supp ose G is (6 , 1) -anonym ous. Finding the smal lest set of e dges to add to G to solve the we ak or str ong (7 , 1) -anonymizat ion pr oblem is NP- har d. The same r esults hold for going fr om ( k , 1) -anonymity to we ak or str ong ( k + 1 , 1) -anonymity when k ≥ 6 . Pr o of. W e show this via a reduction from the 1- in-3 satisfiabilit y p roblem. W e tak e an instance of the 1-in-3 satisfiabilit y problem satisfying the constrain ts of Lemma 1. W e fu r ther assume that the num b er of triples in this instance is a mul- tiple of 3, since if it is not a m u ltiple of 3, it is easy to see that there will b e no satisfying as- signmen t. Since w e also assume that the n u m b er of triples is ev en, the num b er of triples is in fact of th e form 6 m . T aking this instance, we no w form a cub ic bi- partite graph G = ( U, V , E ) b y creating a v ertex in U for eac h triple and a v ertex in V for eac h v ariable, w ith the t w o ve rtices connected by an edge if th e v ariable o ccurs in the trip le. W e add 5 new neighbors of degree 1 to eac h v ertex in U . Eac h of these added n eigh b ors and the v er - tices in V are (7 , 1)-anon ymou s , b ut th e v ertices in U h a v e only 6 vertice s at distance 2, n amely the 2 other neighb ors of eac h of the 3 neigh b ors in V , giving (6 , 1)-anon ym it y . W e would lik e to increase the anon ymity of these v ertices so that they are also (7 , 1)-anon ymous. Note that a so- lution to this an onymit y problem has to consist of at least m edges. This is b ecause the total residual anonymit y of the graph is 6 m and eac h new edge can r educe the residual anon ymity by at most 6. No w , if it w ere p ossib le to select 2 m v ertices in V that we r e adjacent to all the 6 m v ertices in U , w e could ins ert a perf ect matc hin g of m e dges b etw een t hese 2 m ve rtices and sim u l- taneously increase the anon ym ity of all the v er- tices in U by at least 1. T h is w ould corresp ond to a solution to the 1-in-3 satisfiabilit y problem. Similarly , if th er e is a solution to the anonymit y problem that inv olv es the addition of only m edges, it must necessarily corresp ond to a solu- tion to th e 1-in-3 satisfiabilit y problem. Thus a solution to the 1-in-3 s atisfiability prob lem ex- ists if and only if the solution to the anonymit y problem inv olv es the addition of m extra edges. F or k ≥ 6, add k − 2 no des of degree 1 attac hed to eac h v er tex in U . A ttac h an additional no de of degree k − 5 to eac h v ertex in U . At tac h th e remaining k − 6 n eigh b ors of eac h suc h additional no de to a clique of size k + 2. The resu lt then follo ws from the case of k = 6. The complexit y of min im ally obtaining weak and strong ( k, 1)-anonymous graphs remains op en for k = 3 , 4 , 5 , 6. 6 ( k , 1) -anon ymization W e start our stud y for th e ( k , 1)-anon ymization problem b y giving t wo simple O ( k )- appro ximation algo r ithms. W e then sho w that the appro ximation factor can b e fu r ther impro v ed to matc h a lo w er b ound . 6.1 O ( k ) -appro ximation algorithms for ( k , 1) -anon ymization Let G = ( V , E ) b e the input graph to the weak ( k , 1)-anon ymization pr ob lem. C onsider the f ol- lo wing simple iterativ e algorithm: at ev ery step i add to graph G i ( G 1 = G ) a single e dge b et wee n a neigh b or of a deficien t no de u and a no d e that is not already in the 2-neighborh o o d of u in G i . If there are only isolated deficien t no des in G i , the algorithm directly connects a d eficien t no de to a no de of a ( k + 1)-clique. If no such clique 10 exists, the algorithm creates it in a prepro cess- ing step; ( k + 1) rand omly selected no des are pic ked for this purp ose. Rep eat the pro cess un- til no defi cient no des remain. W e call this algo- rithm the Weak- Any algorithm. W e sho w that Weak-Any is an O( k )-appro ximation algorithm for the w eak ( k , 1)-anon ymization prob lem. Th is result is summ arized in the follo wing theorem. Theorem 4. Weak-Any gi ves a O ( k ) - appr oximation for the we ak ( k , 1) -anonymization pr oblem. If the optimal solution is of si ze t , Weak-Any adds at most 4 k t + k 2 e dges. Pr o of. Let R = P v ∈ V r ( v ) b e the residu al anon ymity (see Definition 4) of graph G = ( V , E ). Let W a be the total num b er of edges added by the Weak-Any algo rithm. It holds that W a ≤ R + k 2 . T h is is b ecause at every step the algorithm adds one edge that decreases the residual anon ym it y of the graph by at least 1. Therefore the algorithm add s at most R edges. The additional k 2 edges ma y b e required to cre- ate a ( k + 1)-clique if suc h a clique do es not exist. No w assum e that the optimal solution adds t edges. Consider an edge uv of the optimal so- lution. This edge, at the time of its addition, could hav e d ecreased the residual anonymit y of the graph b y at m ost 4 k . This is b ecause it could ha ve decreased the residual anonymit y of eac h of u and v as wel l as the residual anon ymities of at most k neigh b ors connected to u an d at most k n eigh b ors conn ected to v (if u or v had more than k neigh b ors, th en n one of these neighbors w ould ha v e b een deficien t). F urther, the edge uv could hav e d ecreased the residual anonymit y of u or v by at most k , and the residual anon ymi- ties of eac h of the k neighbors of u or eac h of the k neighbors of v b y at m ost 1. Th us, eac h ed ge of the optimal solution could ha ve reduced the residual anonymit y of the graph by at most 4 k at the time of its add ition. That is, t ≥ R / 4 k . Th us it is clear that W a ≤ 4 k t + k 2 . F or the s trong ( k , 1)-anon ymization problem w e show that the St rong-Any algorithm (v ery similar to Wea k-Any ), is an O( k )-approxima tion. Strong-A ny is also iterativ e: in eac h iteration i it considers graph G i and adds one edge to it. The edge to b e add ed is one that connects a neigh b or of a deficien t no de u to a n o de that is not already in the 2-neigh b orh o o d of u . This pro cess is rep eated till no deficien t no des remain. W e can state the follo wing for the appro ximation ratio ac h iev ed by the Strong-An y algorithm. Theorem 5. Stro ng-Any is a 2 k - appr oximation algorithm for the str ong ( k , 1) -anonymization pr oblem. Pr o of. As in the pr o of of Theorem 4 consider input graph G = ( V , E ) with initial resid- ual anon ym it y R . Every edge added by the Strong-A ny algorithm wo uld r ed uce the residual anon ymity of the graph b y at least 1 . Th erefore, if the num b er o f edges add ed b y the Strong-Any algorithm is Sa we hav e that Sa ≤ R . Supp ose no w th at the optimal solution adds t edges. An added edge uv d ecreases the residual anon ymity of the graph by at most 2 k . This is b ecause the edge can decrease the residual anon ymity of only the original neigh b ors of u and v by at most 1 eac h and there can b e at most 2 k suc h deficient neigh b ors. T h u s t ≥ R/ 2 k . F rom the ab o ve w e hav e that Sa ≤ 2 k t . 6.2 Θ(log n ) -appro ximation algorithms for ( k , 1) -anon ymization W e n o w pro vide tw o sim p le greedy algorithms for the w eak and strong ( k , 1)-anon ymization p rob- lems and show that they output solutions that are O(log n )-appr o ximations to th e optimal. W e then show that this is the b est app ro ximation factor we can hop e to ac hiev e for arbitrary k . W e start by presenti ng We ak-Greedy whic h is an O(log n )-appro xim ation algorithm for the w eak ( k , 1)-anonymiz ation problem. Consider input graph G = ( V , E ) that has total r esidual anon ymity R . The optimal s olution to t he prob- lem consists of a set of edges that together take care of all the residual anon ymity in the graph. W e ma y be tempted to u se a set-co v er t yp e so- lution: greedily c ho ose edges to add that maxi- mally r educe the residual anon y m it y of the graph at eac h step. Ho wev er, such a greedy algorithm is not so easy to analyze in the con text of the w eak-anonymiz ation p roblem. The difficu lty in the analysis stems from the fact that the n ew 11 z1 z2 x3 x1 x2 y1 y2 y3 Figure 3: I llu strativ e example of th e rein- forcemen t b et ween new edges in the w eak- anon ymization pr ob lem. edges ma y r einfor c e eac h other. That is, the ad- dition of an ed ge may brin g ab out a greater r e- duction in the residu al anonymit y of th e graph in the presence of ot her added edges. C onsider, for example, the inp ut graph G shown in Figure 3. Note that solid lin es corresp ond to the original edges in G . In this case, the addition of edge x 2 z 1 alone do es not help in th e anon ymization of no de y 2. (Neit her do es the addition of ed ge y 2 z 1 in the anonymiz ation of x 2). Ho w ever, if edge y 2 z 1 is already added in the graph , then edge x 2 z 1 h elps in anonymizing no d e y 2 as well. W e get around th is p eculiarit y of our prob- lem b y greedily c ho osing triplets of edges to add instead of singleton edges. Algorithm 1, called Weak-Gre edy , describ es the pro cedure. Algorithm 1 Weak-Greed y for w eak ( k , 1)- anon ymization 1: //Input: k , G = ( V , E ) 2: Randomly c ho ose a no de w ∈ V 3: Add up to k +1 2 edges to E to form a k + 1- clique at w 4: Compu te R = r esidual anon ymity of G 5: while R > 0 do 6: Find triplet uv , uw , v w that maximally de- crease R 7: E = E ∪ { uv } ∪ { uw } ∪ { v w } 8: Up date R 9: end while Theorem 6. W eak-Greed y is a p olynomia l-time ne arly O (log n ) -appr o ximation algorithm for the we ak ( k , 1) -anony- mization pr oblem. If the op- timal solution is of size t , the algorithm adds k 2 + 6 t log n e dges. Pr o of. Consider the optimal solution of t edges. These t edges together tak e care of all the resid - ual anon ymity in th e graph. W e can conv ert this solution to a solution of trip lets th at consists of at most k 2 + 3 t edges: first rand omly c ho ose a no de w and create a ( k + 1)-clique amongst w and k other randomly chose n no d es. Then, for eac h edge uv of the optimal solution, add a triangle ( uv , v w , uw ) to the graph. The re- sulting graph will clearly contin ue to b e ( k , 1)- anon ymou s . The t triangles in conjunction with the ( k + 1)-clique tak e care of all the residual anon ymity in the g raph. F urther , these triangles do not r einforce eac h other b ecause they are all connected to a no de of degree k . Going b ac k to Algorithm 1, this means that once a ( k + 1)-clique has b een add ed to the graph , at eac h iteration of the algorithm, there m ust exist some triangle with a vertex in the ( k + 1)- clique that reduces the residual an onymit y of the graph b y a f actor of at least t (similar to the argumen t for the greedy set cov er algorithm). And since the algorithm greedily c ho oses tri- angles to add, the residual anonymit y of the graph will decrease by at least this factor at eac h step. Since the residual anon ymit y of the graph can b e at most k n < n 2 to b egin with, the algorithm will only pro ceed for at most r iterations till (1 − 1 /t ) r ≤ 1 /k n . This w ould mean th at r = O( t log ( k n )) = O(2 t log n ) and 3 r = O(6 t log n ). The app ro ximation algorithm for the strong ( k , 1)-anon y- mization problem is simpler, since added edges cann ot r einforce eac h other — an added ed ge can only h elp th e original neigh b ors of its t wo end p oin ts. Algorithm 2 giv es the de- tails of the St rong-Gree dy a lgorithm. Algorithm 2 Strong- Greedy for ( k , 1)- anon ymization 1: //Input: k , G = ( V , E ) 2: Compute R = residual anon ymity of G 3: while R > 0 do 4: Find edge uv th at maximally reduces R 5: E = E ∪ { uv } 6: Up date R 7: end while Since th e added edges do not reinforce eac h other in the strong ( k , 1)-anon ymization p r ob- 12 lem, the analysis of Strong-Gr eedy is similar to the analysis of the greedy algorithm for the stan- dard set-co ve r p roblem. Theorem 7. Stron g-Greedy is a p olynomial- time 2 log n -appr oximatio n algorithm f or the str ong ( k , 1) -anonymization pr oblem. Pr o of. Supp ose the optimal solution adds t edges, to reduce th e residu al an onymit y of th e graph by at most k n < n 2 . S ince edges of the solution do not r einforce eac h other, there m u st exist s ome edge that redu ces the residu al anon ymity of th e graph by at least a f actor of t . Therefore at eac h iteration of Algorithm 2, w e greedily c ho ose an edge to add that must cause at least th is muc h red u ction in the resid- ual anon y m it y of th e graph. Th e algorithm will th u s terminate after r steps where (1 − 1 /t ) r ≤ 1 / ( kn ), or r = t log( k n ) ≤ 2 t log n . W e next show that log n is the b est factor we could hop e t o ac hiev e for un b ounded k , for b oth the w eak and str on g ( k , 1)-anon ymization p rob- lems via an app ro ximation-preserving reduction from the hitting s et pr oblem. Theorem 8. The we ak and str ong ( k , 1) - anonymizatio n pr oblems with k unb ounde d ar e Ω(log n ) -appr oxima tion NP -har d. Pr o of. Hitting set is Ω(log n )-appr oximati on NP-hard. Consider an instance of the hitting- set problem consisting of sets S = { S 1 , S 2 , . . . } . Let k b e greater than the maxim u m num b er of sets intersecti ng an y on e set S i . Add a u nique elemen t v i to eac h S i . Additionally , construct sets T = { T 1 , T 2 , . . . } suc h that eac h T i con tains the appropr iate v i ’s so that every S i in tersects exactly k − 1 other sets. In every set T i add an additional elemen t w so that eac h set in T in - tersects at least k other sets. No w construct a bipartite graph G = ( U, V , E ), where th e v ertices of U corresp ond to the sets in S and T , the ver- tices of V corresp ond to individ ual members of these sets, with E indicating mem b ership of ele- men ts from V in sets from U . F or ev ery elemen t u in U create ( k + 1) new vertic es of degree 1 in V and connect th em to u . I n the resulting graph, the v ertices in V are all ( k , 1)-anon ymous, how- ev er the vertice s in U that corresp ond to sets in S are only ( k − 1 , 1)-anon ymous. Consider the t no des in V that are the optimal solution to th e hitting-set problem. Then matc hing these no des using ⌈ t/ 2 ⌉ edges will b e an optimal solution to the strong or w eak ( k , 1)-anon ymization p roblem in the bipartite graph G = ( U, V , E ). Therefore, an optimal solution to th e anonymiz ation prob- lem corresp onds to an optimal solution to the hitting-set p roblem which is Ω (log n )-hard to ap- pro x im ate. 7 ( k , ℓ ) -anon ymization for ℓ > 1 In this section w e pro vide algorithms f or the w eak an d strong ( k , ℓ )-anon ym ization problems when ℓ > 1. The algorithm for wea k ( k , ℓ )-anon ymization is a randomized algorithm that constructs a b ound ed-degree exp ander b et wee n defi cien t v er- tices. Giv en a ( k , ℓ ′ )-anon ymous graph G , it solv es th e w eak ( k , ℓ )-anon ym izatio n problem by adding only O( p k − k ′ ) ℓ ) additional edges at eac h v ertex. T he algorithm can also b e easily adapted to solv e the w eak ( k , ℓ )-anonymiza tion problem for any in put graph irresp ectiv e of its initial anonymit y . Theorem 9. Ther e exists a r andom- ize d p olynomia l-time algorithm that adds O ( p ( k − k ′ ) ℓ ) e dges p er v e rtex and incr e ases the anonymity of a gr aph f r om ( k ′ , ℓ ) to ( k , ℓ ) wher e ℓ ≤ k ≤ n 1 − ǫ and ǫ is a c onstant gr e ater than 0 . Pr o of Sketch: Randomly partitio n the n v ertices in to n/ℓ s ets of size ℓ . T r eat eac h set as a “sup erno de”. Constru ct an expander o f degree p ( k − k ′ ) /ℓ on these n /ℓ sup ern o des. In th is w ay eac h s u p erno d e has ( k − k ′ ) ℓ sup erno d es in its 2-neighborh o o d that can b e reac hed th r ough just one in term ed iate sup erno de. Replace eac h edge uv of this expander with a K ℓ,ℓ clique of edges b et ween the constituen t v ertices of the su p erno des u and v . Th us eac h v ertex no w h as k − k ′ v ertices in its 2-neigh b orho o d that can b e reac hed th rough an inte rmediate set of size ℓ . Since l ≤ k ≤ n 1 − ǫ , we can sho w th at with high pr obabilit y , none of these k − k ′ new vertices will coincide with the k ′ 13 v ertices previously in the no de’s 2-neigh b orho o d. As a fi nal result, w e presen t the algorithm for strong ( k , ℓ )-anon ym ization. T h is algo rithm is a generalizat ion of the S trong-Gre edy algorithm (see Alg orith m 2). The d ifference is that instead of p icking a single edge to add at eve ry itera- tion the algorithm picks edges in group s of size at most ℓ . At eac h iteration it p ic ks the group that causes the largest reduction in the resid- ual anonymit y of the graph . The ps eudo co de is giv en in Algorithm 3. Algorithm 3 St rong-Gree dy for ( k , ℓ )- anon ymization 1: //Input: k , ℓ , G = ( V , E ) 2: Compu te R = r esidual anon ymity of G 3: while R > 0 do 4: Find set of edges E , with |E | ≤ ℓ , that maximally reduces R 5: E = E ∪ E 6: Up date R 7: end while W e can state the follo wing theo rem for the ap- pro x im ation f actor of Algorithm 3 when ℓ is a constan t. Theorem 10. Consider G = ( V , E ) to b e the input gr aph to the str ong ( k , ℓ ) -anonymization pr oblem. Also assume ℓ is a c onstant. L et t b e the optimal numb er of e dges that ne e d to b e adde d to solve the str ong ( k , ℓ ) -anonymizatio n pr oblem on G . Then Algorithm 3 is a p oly nomial-time O ( t ℓ − 1 log n ) -appr oxima tion algorithm. Pr o of Sketch: In th e ( k , ℓ )- anon ymization problem, groups of u p to ℓ edges at a time in- ciden t at a single vertex can reduce the residual anon ymity of a v ertex adjacen t to the ℓ endp oin ts of th ese edges. Th e t edges added by the opti- mal solution d efine at most t ℓ subsets o f at most ℓ edges incident to a single v ertex. By selecting suc h subsets greedily as in a set-co ver problem we ultimately reduce the r esidual an onymit y of the graph to 0 in O( t ℓ log n ) steps. W e can sho w that reinforcemen t effects b etw een su bsets of edges are tak en care of. This p ro ves the O ( t ℓ log n ) b ound on the num b er of edges selected. If ℓ is a small constan t, the appr o ximation factor ma y not b e too large . F u r ther, in practice th is simple algorithm ma y p erform b etter th an this worst case b ound indicates. 8 Conclusions Motiv a ted b y recent studies on priv acy- preserving graph r eleases, we prop osed a n ew definition of anonymit y in graphs. W e further defined t wo new com binatorial problems aris- ing f r om this d efinition, studied their complexit y and prop osed simple, effici en t and intuitiv e al go- rithms for solving them. The key idea b ehind our anonymiz ation sc heme was to enforce that ev ery no de in th e graph should share some num b er of its neigh- b ors w ith k other no des. The optimization prob- lems w e d efined ask for the minim u m num b er of edges to b e added to the inp ut graph so that the anon ym ization requirement is satisfied. F or these optimization problems we provided algo- rithms th at solv e them exactly ( k = 2) or ap- pro x im ately ( k > 2). An interesting a ven ue for future w ork would b e to fully c haracterize the kinds of attac ks that our definition of anon ymity p rotects against, and to study the imp act of our anonymizat ion schemes on the utilit y of the graph release. Finally , w e b eliev e that the com bin atorial problems we hav e s tudied in this p ap er are in- teresting in their o w n righ t, and m ay also prov e useful in other domains. F or example, at a high lev el there is a similarit y b etw een the p roblem we study in this pap er and th e p roblem of construct- ing reliable graphs f or, say , reliable routing. References [1] G. Agga rw al, T . F eder, K. Ken thap ad i, R. Motw ani, R. Panigrah y , D. Th omas, a nd A. Zhu. Anon ymizing T ables. In Pr o c e e dings of the International Confer enc e on Datab ase The ory , 2005 . [2] R. Agra wal, R. Sr ik an t, and D. Thomas. Priv acy Preserving OLAP. In Pr o c e e dings of 14 the ACM International Confer enc e on Man- agement of Data , 2005. [3] S. Agra w al and J . Haritsa. A F ramework f or High-Accuracy Pr iv acy-Preserving Mining. In Pr o c e e dings of the International Confer- enc e on Data Engine ering , 2005 . [4] L. Bac kstrom, C. Dwo rk, and J. Klein b erg. Wherefore Art Thou R3579 X? Anon ymized So cial Netw orks, Hidden P atterns, and Structural S teganograph y . In P r o c e e dings of the International World Wide Web Confer- enc e , 2007. [5] A. Evfimievski, J . Gehrke , and R. Srik ant. Limiting Pr iv acy Breac hes in P riv acy Pre- serving Data Minin g. In Pr o c e e dings of the ACM Symp osium on Principles of Dat ab ase Systems , 2003. [6] K. B. F rikke n and P . Golle. Priv ate so cial net work analysis: Ho w to assem b le pieces of a graph priv ately . I n Pr o c e e dings of the 5th ACM Workshop on Privacy in Ele ctr onic So ciety , pages 89–98, Alexandria, V A, 2006. [7] M. Ha y , G. Miklau, D. Jensen, D. T o w sley , and P . W eis. Resisting S tructural Iden tifi- cation in Anonymized So cial Net works. In Pr o c e e dings of the International Confer enc e on V ery L ar ge Data Bases , 2008. [8] A. Korolo v a, R. Mot w ani, S. U. Nabar, and Y. Xu. Link Priv acy in Social Net works. In Pr o c e e dings of the International Confer enc e on Data Eng i ne ering , 2008. [9] K. LeF evre, D. J. DeWitt, and R. Ra- makrishnan. Mondr ian multidimensional k-anon ymity . In Pr o c e e dings of the Inter- national Confer enc e on Data Engi ne ering , page 25, 2006. [10] N. L i, T . Li, and S . V enk atasubramanian. t -Closeness: Priv acy Bey ond k -Anon ymit y and l -Div ers ity. In Pr o c e e dings of the Inter- national Confer enc e on Data Engi ne ering , 2007. [11] A. Mac hana v a jjhala, J. Gehrk e, D. K ifer, and M. V enkitasubramaniam. l -Div er s it y: Priv acy Beyond k -Anonymit y. In Pr o- c e e dings of the International Confer enc e on Data E ng i ne ering , 2006. [12] A. Mey erson and R. Williams. On the com- plexit y of optimal k -anonymit y . In Pr o c e e d- ings of the ACM Symp osium on Principles of Datab ase Systems , 2004 . [13] C . Pa p adimitriou and K. Steiglitz. Com- binatorial Optimization: Algorithms and Complexit y . In Pr entic e-Hal l , 1982. [14] P . Samarati and L. Sweeney . Generalizing Data to Pr o vide Anonymit y when Disclos- ing Inform ation. In Pr o c e e dings of the ACM Symp osium on Principles of D atab a se Sys- tems , 1998. [15] T . J. Sc haefer. The Complexit y of Satisfia- bilit y Problems. In Pr o c e e dings of the An- nual ACM Symp osium on The ory of Com- puting , p ages 216–226 , 1978. [16] X. Ying and X. W u. Randomizing so cial net works: a sp ectrum pr eserving app roac h. In P r o c e e dings of the SIAM Confer enc e on Data M ining , 2008. [17] E . Zhelev a and L. Geto or. Preserving th e priv acy of sensitiv e relationships in graph data. In Pr o c e e dings of the International Workshop on Privacy, Se curity, and T rust in KD D , San Jose, CA, August 2007. [18] B. Zh ou and J . Pei. P reserving Priv acy in So cial Net w orks Against Neighborh o o d At- tac ks. In Pr o c e e dings of the International Confer enc e on Data Engine ering , 2008 . 15
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment