Quantum reinforcement learning
The key approaches for machine learning, especially learning in unknown probabilistic environments are new representations and computation mechanisms. In this paper, a novel quantum reinforcement learning (QRL) method is proposed by combining quantum…
Authors: Daoyi Dong, Chunlin Chen, Hanxiong Li
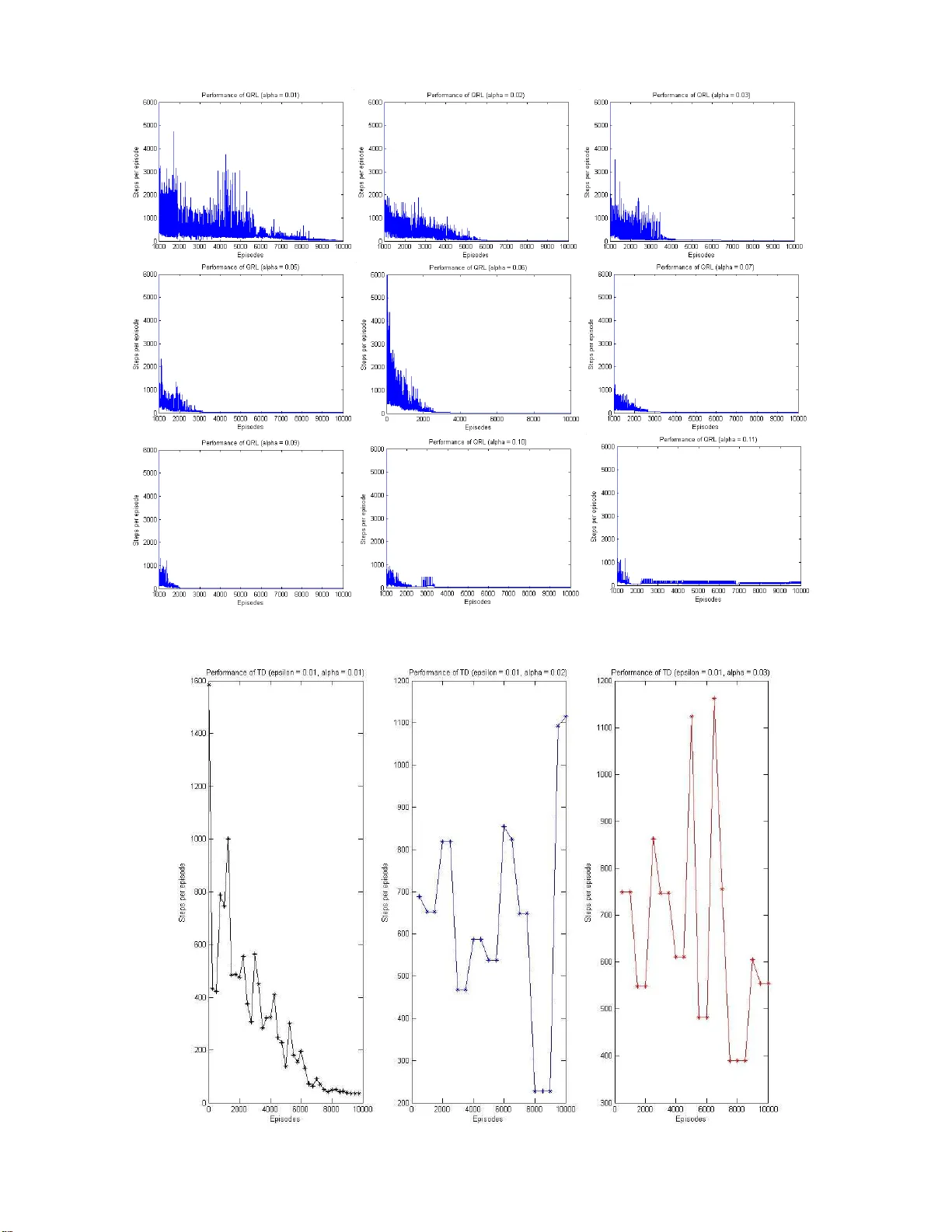
1 Quantum Reinforceme nt Learning Daoyi Dong, Chu nlin Chen, Ha nxiong Li, Tz yh-Jong T arn Abstract — The key approaches fo r machine learning, especially learning in un known probabilistic en viro nments are new repre- sentations and computation mechanisms. In th is p aper , a novel quantum reinforc ement learning (QRL) method is proposed by combining quantum theory and reinfor cement learning (RL). Inspired by the state su perposition principle and qu an tum par - allelism, a framew ork of value updating algorithm is introduced. The sta te (action) in traditional RL is iden tified as the eigen state (eigen action) in QRL. The state (action) set can be repr esented with a quantu m superposition state a nd the eigen state (eigen action) can b e obtained b y randomly observing the simulated quantum state according to the collapse postulate of quantum measureme nt. The probability of the eigen action is determined by t he probability amplitud e, which is parallelly up dated ac- cording t o rewards. Some related characteristics of QRL such as con v ergence, optimality and balancing b etween exploration and exploitation are also analyzed, which sh ows that this app roach makes a good tradeoff between exploration and exploitation using the probability amplitu de and can sp eed up learning th rough the quantum parallelism. T o e valuate the perf ormance and practicability of QRL, severa l simulated experiments a re giv en and the results demonstrate the effectiveness and sup eriority of QRL algorithm for some complex p roblems. Th e present work is also an effectiv e exploration on th e application of quant u m computation to artifi cial intelligence. Index T erms — quantu m reinf orc ement learning, state super - position, collapse, p robability amplitud e, Gro ver iteration. I . I N T R O D U C T I O N L EARNING methods are generally classifi ed into super- vised, unsuper vised and r e in for cement learning ( RL). Supervised learn ing requir es explicit feedbac k provided by input-o utput pairs and gives a map f rom inputs to outputs. Unsuperv ised learning only processes on the input data. In contrast, RL uses a scalar value nam ed re war d to evaluate the input-o utput pa irs an d lear ns a mapp ing fro m states to actions by interaction with the environment through trial-and- error . Sin ce 1980s, RL has become an importan t approac h to ma chine learning [1]-[22], a nd is widely used in ar tificial intelligence, esp ecially in robo tics [ 7]-[1 0], [18], due to its good perfo rmance of on -line adaptation and powerful lear ning ability to c omplex nonlin ear systems. Howe ver there are still some dif ficult pro blems in pr actical ap plications. One This work was supported in part by the National Natural Scienc e Founda- tion of China under Grant No. 60703083, the K. C. W ong Education Founda- tion (Hong Kong), the China Postdoctora l Science Foundation (20060400515) and by a grant from RGC of Hong Kong (CityU:11640 6). D. Dong i s with t he K e y Laboratory of Systems and Control, Institute of Systems Science , A MSS, Chinese Academy of Scienc es, Beijing 100190, China (email: dydong@amss.ac.cn). C. Chen is with the Department of Control and System E nginee ring, Nanjing Unive rsity , Nanjing 210093, China (email: clche n@nju.edu.c n). H. L i is with the Central South Uni ver sity , Changsha 410083, China and the Department of Manufacturi ng Engineeri ng and Engineer ing Management, City Uni ver sity of Hong Kong, Hong Kong. T . J. T arn is with the Department of Electri cal and Systems Engineering, W ashington Uni versi ty in St. Louis, St. Louis, MO 63130 USA. problem is the explor ation strategy , wh ich con tributes a lo t to better balancing o f explor ation ( trying pr eviously unexplor ed strategies to find better p olicy) and exploitation ( taking the most ad vantage o f the e xperienced kn owledge). The other is its slow lear ning speed, especially for th e complex problems sometimes known as “th e c urse of dimen sionality” when the state-action space becomes huge and the number of parameters to be learn ed grows expone ntially with its dimension. T o comb at those problems, many method s have been pro- posed in recent years. T emporal abstraction and decomposition methods h av e been explored to solve such prob lems as RL and dynam ic progr amming (DP) to speed up lea rning [ 11]- [15]. Dif ferent kinds of learning paradigms ar e combined to optimize RL. For example, Smith [16] pr esented a new m odel for r epresentation a nd generalizatio n in mod el-less RL based on the self-organ izing map (SOM) and standard Q-lear ning. The adap tation of W atkins’ Q-learning with fu zzy inferenc e systems for pr oblems with large state-a ction sp aces or with continuo us state spaces is also p roposed [6], [17], [18], [1 9]. Many specific imp rovements ar e also implem ented to mo dify related RL metho ds in practice [7] , [9], [10], [ 20], [21], [22]. I n spite o f all th ese a ttempts mo re work is need ed to achieve satisfactory successes and new ideas are necessary to explore m ore effective represen tation m ethods and learning mechanisms. In this paper , we explore to overcome some difficulties in R L using q uantum theory and pr opose a novel quantum reinfor cement learn ing method. Quantum info rmation processing is a rapidly developing field. Some results have shown that quan tum computation can m ore efficiently solve some d ifficult prob lems than the classical counte rpart. T wo im portant quantu m alg orithms, the Shor alg orithm [2 3], [ 24] and the Grover algorith m [25], [26] have been pro posed in 1994 and 1996 , re spectiv ely . Th e Shor algorithm can g i ve an expon ential speedup f or factor ing large integers into pr ime numb ers and it has been realized [27] for the factorization o f integer 15 using n uclear mag- netic resonance (NMR). The Grover algorithm can achieve a square speedup over classical algorithm s in u nsorted database searching and its experimental implementations ha ve also been demonstra ted using NMR [ 28]-[30] and q uantum optics [3 1], [32] for a system with four states. Some meth ods h av e also been explo red to co nnect q uantum compu tation and mach ine learning. For example , the quantu m computing version of artificial ne ural n etwork has been studied f rom the p ure th eory to the simple si mulated and experimental i mplementatio n [33]- [37]. Rigatos an d Tzafestas [38] u sed quan tum computation for the p arallelization o f a fu zzy lo gic contro l algo rithm to speed up the f uzzy inference. Quantum or quantum-inspired ev olutionary alg orithms have been pro posed to improve the existing ev olutionary algor ithms [3 9]. Ho gg and Portnov [40] presented a qua ntum algor ithm for combin atorial optimiza- 2 tion of overconstrained satisfiability (SA T) and asy mmetric trav elling salesma n (A TSP). Recently the qu antum search technique has been used to dynamic progr amming [ 41]. T a king advantage of quantu m compu tation, some novel algorithm s inspired b y quan tum characteristics will not only improve th e perfor mance o f existing a lgorithms o n tr aditional co mputers, but a lso pro mote the d ev elopment o f related resear ch areas such as q uantum computers and machine le arning. C onsidering the essence o f comp utation and algorith ms, Dong and his co- workers [4 2] have presented the con cept of quantum r ein- for cement learning (QRL) inspired by the state superpo sition principle an d quantu m parallelism. Follo wing th is co ncept, we in this paper giv e a fo rmal q uantum rein forceme nt learning algorithm f ramework and specifically demon strate the advan- tages of QRL fo r speedin g up lea rning and o btaining a goo d tradeoff b etween e xploration and e xploitation of RL thr ough simulated experimen ts and some related discussions. This paper is organized as follows. Section II contain s the prerequ isite an d problem description of stand ard reinforcement learning, quantum co mputation and rela ted q uantum gates. In Sec tion I II, quantum reinfo rcement learning is intro duced systematically , where th e state (actio n) sp ace is r epresented with the quantum state, the explor ation strategy based on th e collapse po stulate is achie ved and a n ovel QRL algorithm is propo sed specifically . Section IV analyzes related character- istics of QRL suc h as the co n vergence, op timality and the balancing between exploration and e xploitation. Section V describes the simulated exper iments and the resu lts demon - strate the ef fecti veness and su periority of QRL algorithm. In Section VI, we br iefly d iscuss some related pr oblems o f QRL for future work. Con cluding remarks are g iv en in section VI I. I I . P R E R E Q U I S I T E A N D P RO B L E M D E S C R I P T I O N In this section we first b riefly r evie w the standard reinf orce- ment learning algorithm s an d the n in troduce the backgroun d of quan tum co mputatio n and some r elated quantu m g ates. A. Reinfor cement lea rning (RL) Standard framework of reinfo rcement learn ing is based on discrete-time, fin ite-state Mar kov decision processes (MDPs) [1]. Definition 1 ( MDP ): A Markov decision pro cess (MDP) is comp osed of the following fi ve factors: { S, A ( i ) , p ij ( a ) , r ( i,a ) , V , i, j ∈ S, a ∈ A ( i ) } , where: S is the state space; A ( i ) is the actio n space fo r state i ; p ij ( a ) is th e pr obability f or state transition; r is a reward fun ction, r : Γ → ( −∞ , + ∞ ) , where Γ = { ( i, a ) | i ∈ S, a ∈ A ( i ) } ; V is a criterio n functio n or objective f unction. According to the definition of MDP , we k now that th e MDP h istory is c omposed of successi ve states an d decisions: h n = ( s 0 , a 0 , s 1 , a 1 , . . . , s n − 1 , a n − 1 , s n ) . The p olicy π is a sequence: π = ( π 0 , π 1 , . . . ) , wh en the history at n is h n , the strategy is adop ted to make a d ecision accor ding to the probab ility distribution π n ( •| h n ) on A ( s n ) . RL algorith ms assume that the state S and action A ( s n ) can be divided in to discrete values. At a certain step t , the agent observes th e state of the environment (in side and o utside of the agent) s t , and then choose an action a t . After executing the action, the agent recei ves a re w ard r t +1 , which reflects how good that action is (in a sh ort-term sense). The state o f the en vironmen t will ch ange to next state s t +1 under the action a t . The ag ent will choo se the next action a t +1 accordin g to related knowledge. The goal of rein forcemen t learning is to lear n a mapping from states to actions, that is to say , the agent is to lea rn a policy π : S × ∪ i ∈ S A ( i ) → [0 , 1 ] , so that th e expected sum of discounted reward of each state will be m aximized: V π ( s ) = E { r ( t +1) + γ r ( t +2) + . . . | s t = s, π } = E [ r ( t +1) + γ V π s ( t +1) | s t = s, π ] = X a ∈ A s π ( s, a )[ r a s + γ X s ′ p a ss ′ V π ( s ′ ) ] (1) where γ ∈ [0 , 1] is a discoun t factor, π ( s, a ) is th e prob ability of selecting action a according to state s und er policy π , p a ss ′ = P r { s t +1 = s ′ | s t = s, a t = a } is the pro bability for state transition and r a s = E { r t +1 | s t = s, a t = a } is the expected one-step reward. V ( s ) (or V ( s ) ) is also called th e value fun ction of state s an d the tempo ral difference (TD) one-step updatin g r ule of V ( s ) may be described as V ( s ) ← V ( s ) + α ( r + γ V ( s ′ ) − V ( s )) (2) where α ∈ (0 , 1) is the learn ing rate. W e have the op timal state-value functio n V ∗ ( s ) = max a ∈ A s [ r a s + γ X s ′ p a ss ′ V ∗ ( s ′ ) ] (3) π ∗ = arg max π V π ( s ) , ∀ s ∈ S (4) In d ynamic prog ramming , (3) is also called the Bellman equation of V ∗ . As for state-actio n pairs, the re are similar value fu nctions and Bellman equatio ns, and Q π ( s,a ) stands for the value of taking the action a in the state s und er the policy π : Q π ( s,a ) = E { r ( t +1) + γ r ( t +2) + . . . | s t = s, a t = a, π } = r a s + γ X s ′ p a ss ′ V π ( s ′ ) = r a s + γ X s ′ p a ss ′ X a ′ π ( s ′ , a ′ ) Q π ( s ′ ,a ′ ) (5) Q ∗ ( s,a ) = max π Q ( s,a ) = r a s + γ X s ′ p a ss ′ max a ′ Q π ( s ′ ,a ′ ) (6) Let α be the learning rate, and the one-step updating ru le of Q-learnin g ( a widely used RL algorithm ) [5] is: Q ( s t , a t ) ← (1 − α ) Q ( s t , a t ) + α ( r t +1 + γ ma x a ′ Q ( s t +1 , a ′ )) (7) There are many effectiv e standard RL algorithms like Q- learning, for examp le TD( λ ), Sarsa, etc. For more d etails see [1]. 3 B. State superposition an d quantu m parallelism Analogou s to classical bits, the fundam ental concept in quantum computation is the quantum b it ( qubit ). The two basic states for a q ubit are deno ted as | 0 i and | 1 i , which c orrespon d to the states 0 and 1 fo r a classical b it. Howe ver , besides | 0 i or | 1 i , a qubit can also lie in the superposition state of | 0 i and | 1 i . In oth er words, a q ubit | ψ i can generally be expressed as a linear co mbination of | 0 i and | 1 i | ψ i = α | 0 i + β | 1 i (8) where α and β are com plex coefficients. This special quantu m pheno menon is called state s uperposition princ ip le , which is an im portant dif ference between classical co mputation an d quantum com putation [ 43]. The phy sical carr ier of a qubit is any two-state quantu m system such as a two-level atom, spin- 1 2 particle a nd p olarized photon . For a physical qubit, wh en we select a set o f bases | 0 i or | 1 i , we ind icate that an o bservable ˆ O of the qub it system h as b een ch osen an d the bases correspo nd to the two eigenv ectors of ˆ O . For convenience, the m easuremen t proce ss on the observable ˆ O of a quan tum system in correspo nding state | ψ i is d irectly called a measuremen t of qu antum state | ψ i in this p aper . When we measure a qubit in supe rposition state | ψ i , th e qub it system w ould collapse into one of its basic states | 0 i or | 1 i . Howe ver , we cannot d etermine in advance wh ether it will collapse to state | 0 i or | 1 i . W e only know that we get this qub it in state | 0 i with probab ility | α | 2 , or in state | 1 i with probability | β | 2 . Hence α and β are generally c alled pr obability amplitud es . The magn itude and argument of pro bability amplitud e r epresent amplitu d e and phase , respectively . Since the sum of prob abilities mu st be equal to 1 , α and β should satisfy | α | 2 + | β | 2 = 1 . According to quantu m co mputation theory , a funda mental operation in th e quantu m com puting process is a unitary transform ation U on the q ubits. If on e applies a transfo rmation U to a superposition state, the transformation will ac t on all basis vectors of this state and th e output w ill be a new superpo sition state obtained by superpo sing the results of all basis vectors. It seems that the transfo rmation U can simultaneou sly e valuate the different v alues of a fu nction f ( x ) for a certain input x a nd it is called q uantum pa rallelism . The quantum parallelism is one of the most important factors to acquire the powerful ability o f q uantum alg orithm. Howe ver , note that this parallelism is not immediately usefu l [4 4] since the direct me asurement on the output generally gi ves only f ( x ) for on e value of x . Suppo se the input q ubit | z i lies in the superpo sition state: | z i = α | 0 i + β | 1 i (9) The transformation U z which descr ibes co mputing pr ocess may be define d as follows: U z : | z , 0 i → | z , f ( z ) i (10) where | z , 0 i represen ts the join t inp ut state with the first qubit in | z i and th e second q ubit in | 0 i , and | z , f ( z ) i is the joint output state with the fir st qub it in | z i and the second qub it in | f ( z ) i . According to eq uations (9 ) an d ( 10), we can easily obtain [44]: U z | z , 0 i = α | 0 , f (0) i + β | 1 , f (1) i (11) The r esult con tains in formation ab out bo th f (0) a nd f (1) , and we seem to ev aluate f ( z ) f or two values of z simultaneously . The abov e pro cess co rrespond s to a “ quan tum black box ” (or oracle). By feedin g quan tum superpo sition states to a q uantum black bo x, we can learn what is inside with an exponential speedup, comp ared to h ow long it would take if we were on ly allowed classical in puts [43]. Now con sider an n -qubit system, which can b e represen ted with tensor pro duct of n qu bits: | φ i = | ψ 1 i ⊗ | ψ 2 i ⊗ . . . | ψ n i = 11 ... 1 X x =00 ... 0 C x | x i (12) where ‘ ⊗ ’ mean s tensor prod uct, P 11 ... 1 x =00 ... 0 | C x | 2 = 1 , C x is complex co efficient and | C x | 2 represents occur rence pro b- ability of | x i when state | φ i is me asured. x can take on 2 n values, so the superpo sition state can be looked upo n as the superpo sition of all integer s from 0 to 2 n − 1 . Since U is a unitary transfor mation, com puting fu nction f ( x ) can result [43]: U 11 ... 1 X x =00 ... 0 C x | x, 0 i = 11 ... 1 X x =00 ... 0 C x U | x, 0 i = 11 ... 1 X x =00 ... 0 C x | x, f ( x ) i (13) Based on the above analysis, it is easy to find th at an n -qubit system can simultaneously process 2 n states althou gh only one of th e 2 n states is accessible th rough a direct measurem ent and the ability is r equired to extract information about mor e than one value of f ( x ) fro m the o utput sup erposition state [44]. This is different from classical parallel computatio n, where m ultiple circu its built to compu te are executed simulta- neously , since quantum para llelism doe sn’t n ecessarily make a tradeo ff betwee n compu tation time and needed physical space. In fact, q uantum parallelism emp loys a single circu it to simultaneously evaluate th e function fo r multiple values by exploiting the q uantum state sup erposition prin ciple an d provides an exponen tial-scale compu tation space in the n - qubit linear physical space. Theref ore quantum computation can effecti vely increase the computin g speed o f som e imp ortant classical functio ns. So it is p ossible to obta in sign ificant result throug h fusing the quan tum comp utation into the reinforc e- ment learnin g the ory . C. Qu a ntum Gates In the classical comp utation, th e log ic o perator s that can complete some specific tasks are called logic ga tes , such as NO T gate, AND gate, XOR gate, a nd so o n. Analo gously , quantum co mputing tasks can b e comp leted throu gh q uantum gates . Now adays some simple quantum gates such as quan - tum NOT gate and quantu m CNO T gate have been built in quantum compu tation. Here we on ly in troduce two imp ortant quantum gates, Had a mar d gate an d ph ase ga te , which are closely relate d to accomp lish some qu antum log ic oper ations 4 for th e p resent q uantum rein forcem ent lear ning. The deta iled discussion ab out quan tum g ates can be f ound in th e Ref. [44]. Hadamard g ate (or Hadamard transfo rm) is one o f the most useful quan tum gates and can be represented as [44]: H ≡ 1 √ 2 1 1 1 − 1 (14) Throu gh Hadamard gate, a qubit in the state | 0 i is tr ansformed into a n equally we ighted superpo sition state of | 0 i an d | 1 i , i. e. H | 0 i ≡ 1 √ 2 1 1 1 − 1 1 0 = 1 √ 2 | 0 i + 1 √ 2 | 1 i (15) Similarly , a qu bit in the state | 1 i is transform ed in to the superpo sition state 1 √ 2 | 0 i − 1 √ 2 | 1 i , i.e. the magnitude of the amplitude in each state is 1 √ 2 , but the phase of th e amplitude in the state | 1 i is in verted. In classical probabilistic algorithms, the phase h as no analog since the amplitud es are in general complex number s in quan tum mechanics. The o ther related qu antum g ate is the phase gate (co ndi- tional pha se shift o peration ) which is a n impor tant elemen t to carry out the Grover iteration for re inforcin g “g ood” decision . According to qu antum informatio n theory , this transform ation may be efficiently implem ented o n a quantu m compu ter . For example, th e transfor mation d escribing this fo r a two-state system is of th e for m: U phase = 1 0 0 e iϕ (16) where i = √ − 1 and ϕ is arbitrar y r eal num ber [26]. I I I . Q UA N T U M R E I N F O R C E M E N T L E A R N I N G ( Q R L ) Just like the traditiona l reinfor cement lear ning, a quantum reinfor cement lear ning system can also b e iden tified for th ree main subelements: a policy , a reward function and a mode l of the environmen t (may be not explicit). But q uantum rein- forcemen t learn ing algorithms are remarka bly different from all those tr aditional RL algorithms in the following intrin sic aspects: rep resentation, policy , parallelism and u pdating op er- ation. A. Repr esentation As we r epresent a QRL sy stem with quantu m concepts, similarly , we hav e the follo wing definitions an d p roposition s for quan tum rein forcemen t learning . Definition 2 ( E igen states ( or eigen action s)): Select a n observable o f a quantu m system and its eigen vecto rs f orm a set of comp lete orth onorm al bases in a Hilbert space. The states s (o r a ctions a ) in Definition 1 a re denoted as the correspo nding orth ogona l bases and ar e c alled the eigen states or eigen action s in QRL. Remark 1: In the rem ainder o f this paper, we indicate that an obser vable h as be en chosen but we do n ot present the observable specifically when mentio ning a set of orthogo nal bases. Fro m Defin ition 2, we can g et the set of eig en states: S , and that o f eigen actio ns f or s tate i : A ( i ) . The eigen state (eigen action) in QRL correspo nds to the state ( action) in tradition al RL. Accordin g to qua ntum mech anics, the q uantum state f or a general closed qu antum system can be represented with a unit vector | ψ i ( Dirac rep resentation) in a Hilb ert space. Th e inner prod uct of | ψ 1 i and | ψ 2 i can b e written into h ψ 1 | ψ 2 i and the nor malization conditio n fo r | ψ i is h ψ | ψ i = 1 . As the simplest quantu m mechan ical system, th e state of the qu bit can be d escribed as (8) and its normalization condition is equiv alent to | α | 2 + | β | 2 = 1 . Remark 2: Accord ing to th e sup erposition prin ciple in quantum comp utation, since a quan tum reinfor cement learning system can lie in som e orthogo nal qu antum states, which correspo nd to the eigen states (eig en ac tions), it can a lso lie in an ar bitrary super position state. That is to say , a Q RL system which can take on the states (or actio ns) | ψ n i is also able to occupy their linear super position state (or actio n) | ψ i = X n β n | ψ n i (17) It is worth n oting that this is only a representation method a nd our goal is to ta ke adv antage of the quantum ch aracteristics in the learning pr ocess. In fact, the st ate (action) in QRL is not a practical state (a ction) and it is only an artificial state (action) for c omputin g conv enience with quantum sy stems. The practica l state ( action) is the eigen state (eige n actio n) in QRL. For an arbitrar y state (or actio n) in a quantum reinfor cement learning sy stem, we can ob tain Proposition 1. Pr o position 1: An arbitrary state | S i ( or action | A i ) in QRL can be expanded in ter ms of an o rthogo nal set of eigen states | s n i (or eigen actions | a n i ), i.e. | S i = X n α n | s n i (18) | A i = X n β n | a n i ( 19) where α n and β n are prob ability am plitudes, and satisfy P n | α n | 2 = 1 and P n | β n | 2 = 1 . Remark 3: The states and actions in QRL are different from those in traditional RL: (1) The sum o f several states ( or actions) does not hav e a definite meaning in tr aditional RL, but the sum of states (or actions) in QRL is still a possible state (or action) of th e same quantum system. (2 ) When | S i takes on an eigen state | s n i , it is exclusive. Otherwise, it h as the p robability of | α n | 2 to b e in the eigen state | s n i . T he sam e analysis also is suitable to the actio n | A i . Since quantu m compu tation is built upo n the c oncept of qubit as what has been de scribed in Sectio n II, for the conv enience of p rocessing, we consider to use multip le qubit systems to express states and actions and pro pose a f ormal representatio n of them for the QRL system. L et N s and N a be the numbe r of states an d action s, then ch oose numb ers m and n , which ar e chara cterized by th e following inequalities: N s ≤ 2 m ≤ 2 N s , N a ≤ 2 n ≤ 2 N a (20) And use m and n q ubits to represent eigen state set S = {| s i i} and eigen action set A = {| a j i} respe ctiv ely , we can obtain the correspo nding relatio ns as fo llows: | s ( N s ) i = N s X i =1 C i | s i i ↔ | s ( m ) i = m z }| { 11 · · · 1 X s =00 ··· 0 C s | s i (21) 5 | a ( N a ) s i i = N a X j =1 C j | a j i ↔ | a ( n ) s i = n z }| { 11 · · · 1 X a =00 ··· 0 C a | a i (22) In other words, the states (or actio ns) of a QRL system may lie in the superposition state of eigen states (or eigen actio ns). Inequa lities in (20) guaran tee that every states an d actions in traditional RL have correspond ing representation with eige n states an d eig en ac tions in QRL. The p robab ility amplitude C s and C a are com plex nu mbers and satisfy m z }| { 11 · · · 1 X s =00 ··· 0 | C s | 2 = 1 (23) n z }| { 11 · · · 1 X a =00 ··· 0 | C a | 2 = 1 (24) B. Action selection po licy In QRL, the agent is also to learn a policy π : S × ∪ i ∈ S A ( i ) → [0 , 1] , which will maxim ize the expected sum of discounted reward o f each state. That is to say , the mapping from states to actions is π : S → A , and we have f ( s ) = | a ( n ) s i = n z }| { 11 · · · 1 X a =00 ··· 0 C a | a i (25) where probab ility amplitude C a satisfies ( 24). He re, the ac tion selection policy is based o n the collap se postulate: Definition 3 ( A ction collapse): When an action | A i = P n β n | a n i is measure d, it will be chang ed and co llapse r an- domly into one o f its eigen actions | a n i with the correspon ding probab ility |h a n | A i| 2 : |h a n | A i| 2 = | ( | a n i ) ∗ | A i| 2 = | ( | a n i ) ∗ X n β n | a n i| 2 = | β n | 2 (26) Remark 4: Accord ing to Definitio n 3, when an action | a ( n ) s i in (25) is measur ed, we will get | a i with the occurr ence probab ility of | C a | 2 . In QRL algorith m, we will am plify the prob ability of “good” action accor ding to correspond ing rew ards. It is obvious that the collapse a ction selection m ethod is not a real action selection policy theoretically . I t is ju st a fundam ental phenom enon whe n a qu antum state is measured, which results in a good balan cing between exploration a nd exploitation an d a natural “action selection” with out setting parameters. More detailed discussion about the action selection can also be found in Ref. [45] C. P aralleling state va lue upda ting In Pro position 1, we pointed out th at every possible state of QRL | S i can be expan ded in terms of an or thogon al comple te set o f e igen states | s n i : | S i = P n α n | s n i . According to quantum parallelism, a certain unitar y tran sformation U o n the qubits can be implem ented. Sup pose we ha ve such an operation which can simu ltaneously pro cess these 2 m states with the TD(0 ) value upd ating rule V ( s ) ← V ( s ) + α ( r + γ V ( s ′ ) − V ( s )) (27) where α is th e learnin g rate, an d the meaning o f reward r and value fu nction V is the same as th at in traditional RL. I t is like p arallel value updating o f trad itional R L over all states. Howe ver , it provides an exponential- scale computation space in the m -qub it linear p hysical spac e and c an speed up the solutions of related functions. In this paper we will simulate QRL p rocess o n th e trad itional c omputer in Section V . How to realize some specific functio ns of the algorithm using quantu m gates in detail is our future work . D. P r ob ability amplitu d e u p dating In QRL, action selection is executed by measuring ac tion | a ( n ) s i related to certain state | s i , which will collapse to | a i with the o ccurren ce prob ability o f | C a | 2 . So it is n o doub t that probab ility am plitude updating is the key of r ecording the “trial-and- error” experience an d learning to be mo re intelli- gent. As the action | a ( n ) s i is the super position of 2 n possible eigen actions, finding out | a i is u sually interacting with chan ging its probab ility amplitud e fo r a qua ntum system. Th e updating of probab ility amplitude is based on the Grover iteratio n [2 6]. First, p repare the equally weighted super position of all e igen actions | a ( n ) 0 i = 1 √ 2 n ( n z }| { 11 · · · 1 X a =00 ··· 0 | a i ) (28) This process can be done easily by applying n Had amard gates in sequenc e to n in depend ent qubits with initial states in | 0 i respectively [26], which can b e represented into: H ⊗ n | n z }| { 00 · · · 0 i = 1 √ 2 n ( n z }| { 11 · · · 1 X a =00 ··· 0 | a i ) (29) W e know that | a i is an eigen a ction, irrespective of the value of a , so that |h a | a ( n ) 0 i| = 1 √ 2 n (30) T o construct the Grover iteration we will comb ine two reflections U a and U a ( n ) 0 [44] U a = I − 2 | a ih a | (31 ) U a ( n ) 0 = H ⊗ n (2 | 0 ih 0 | − I ) H ⊗ n = 2 | a ( n ) 0 ih a ( n ) 0 | − I (32) where I is unitary matrix with app ropriate dimen sions and U a correspo nds to the oracle O in th e Grover algo rithm [4 4]. The external product | a ih a | is defined | a ih a | = | a i ( | a i ) ∗ . Obviously , we have U a | a i = ( I − 2 | a ih a | ) | a i = | a i − 2 | a i = −| a i (33) U a | a ⊥ i = ( I − 2 | a ih a | ) | a ⊥ i = | a ⊥ i (34) 6 Fig. 1. The s chemati c of a single Grover iteration. U a flips | a s i into | a ′ s i and U a ( n ) 0 flips | a ′ s i into | a ′′ s i . One Grover iteration U Gro v rotate s | a s i by 2 θ . where | a ⊥ i represents an arbitrar y state orthogon al to | a i . Hence U a flips the sign of th e action | a i , but acts tr ivially on any action ortho gonal to | a i . T his transfo rmation h as a simple geom etrical interp retation. Acting on any vector in the 2 n -dimension al Hilber t spac e, U a reflects th e vector ab out th e hyperp lane orth ogonal to | a i . Analo gous to the ana lysis in the Grover algo rithm, U a can be lo oked u pon as a quantum black box , wh ich can effecti vely justify whether th e action is the “good” eigen action. Similarly , U a ( n ) 0 preserves | a ( n ) 0 i , but flips the sign of any vector o rthogo nal to | a ( n ) 0 i . Thus on e Grover iteration is the u nitary transfor mation [28], [44] U Gr ov = U a ( n ) 0 U a (35) Now let’ s consider how the Grover itera tion a cts in the plane spanned by | a i and | a ( n ) 0 i . The initial action in equ ation (28) can be r e-expressed as f ( s ) = | a ( n ) 0 i = 1 √ 2 n | a i + r 2 n − 1 2 n | a ⊥ i (36) Recall that |h a ( n ) 0 | a i| = 1 √ 2 n ≡ sin θ (37) Thus f ( s ) = | a ( n ) 0 i = sin θ | a i + co s θ | a ⊥ i . (38) This pr ocedur e of Grover iteration U Gr ov can b e visua lized geometrica lly by Fig. 1. This figure shows th at | a ( n ) 0 i is rotated b y θ from th e axis | a ⊥ i n ormal to | a i in the plane. U a reflects a vector | a s i in the plane a bout the axis | a ⊥ i to | a ′ s i , and U a ( n ) 0 reflects the vector | a ′ s i ab out the axis | a ( n ) 0 i to | a ′′ s i . Fr om Fig . 1 we kn ow that α − β 2 + β = θ (39) Thus we have α + β = 2 θ . So one Grover iteration U Gr ov = U a ( n ) 0 U a rotates any vector | a s i by 2 θ . W e now can carr y out a certain times o f Grover iteratio ns to upda te the pro bability amplitudes accordin g to respective rew ards and value function s. It is o bvious that 2 θ is the updating stepsize. Thus when an action | a i is executed, the Fig. 2. The eff ect of Grover iterat ions in Grove r algori thm and QRL. (a) Initia l state; (b) Grover iterati ons for amplifying | C a | 2 to almost 1; (c) Grove r iterat ions for reinforcing action | a i to probability sin 2 [(2 L + 1) θ ] probab ility amp litude of | a ( n ) s i is updated b y carry ing out L = int ( k ( r + V ( s ′ ))) times o f Gr over iterations, wher e int ( x ) returns the integer p art of x . k is a par ameter which in dicates that the time s L of iterations is prop ortional to r + V ( s ′ ) . The selection of its value is experiential in this paper and its optimization is an open question . The pr obability amplitudes will be norm alized with P a | C a | 2 = 1 after each updating . According to Ref. [46], we k now that applying Gr over iteration U Gr ov for L times o n | a ( n ) 0 i can be represented as U L Gr ov | a ( n ) 0 i = sin[(2 L + 1) θ ] | a i + cos[(2 L + 1 ) θ ] | a ⊥ i (40) Obviously , we can reinfor ce the action | a i from pro bability 1 2 n to sin 2 [(2 L +1) θ ] throu gh Gr over iterations. Since sin(2 L +1) θ is a p eriodical function a bout (2 L +1 ) θ and too much itera tions may also cause small p robability sin 2 [(2 L + 1) θ ] , we further select L = min { int ( k ( r + V ( s ′ ))) , int ( π 4 θ − 1 2 ) } . Remark 5: The probab ility amp litude updating is insp ired by the Grover algorith m and the two proce dures use the same amplitude amplificatio n techniq ue as a subrou tine. Here we want to emphasize the difference betwe en the proba bility amplitude updating and Grover’ s datab ase searching algo- rithm. Th e objective of Grover algorithm is to search | a i by amplifyin g its o ccurren ce pr obability to a lmost 1, h owe ver , the aim of pro bability amplitud e upd ating pro cess in QRL just app ropriately updates (am plifies or shrin ks) corr espondin g amplitudes for “go od” o r “bad ” eig en actions. So th e essential difference is in th e times L of iterations and this can be demonstra ted by Fig. 2. E. QRL algo rithm Based on the above discussion, the p rocedu ral form of a stan dard QRL algo rithm is describ ed as Fig. 3. I n QRL algorithm , after initializing the state and action we can o bserve | a ( n ) s i an d o btain an eigen action | a i . Execute this a ction and the system can give ou t next state | s ′ i , rew ard r and state value V ( s ′ ) . V ( s ) is updated by TD(0) rule, a nd r and V ( s ′ ) ca n be used to dete rmine the iteration times L . T o accomplish the task in a practical computing d evice, we require som e basic registers for the storage of r elated info rmation. Firstly two m - qubit registers are r equired fo r all eigen states an d their state values V ( s ) , respectively . Secondly every eig en state r equires 7 Fig. 3. The algorit hm of a standard quantum reinforcemen t learning (QRL) two n -q ubit registers for their r espective eigen actions stored for two times, whe re on e n -qubit r egister stores the action | a ( n ) s i to be ob served and the other n -qub it register also stores the same action for preventing the memo ry lo ss associated to the action collapse. It is worth mentionin g that this does not con flict with the no-clon ing theo rem [44] since the action | a ( n ) s i is a cer tain k nown state at each step. Fin ally several simple classical registers may be requ ired for the rew ard r , the times L , and etc. Remark 6: QRL is inspired by the super position princ iple of qua ntum state and q uantum parallelism. The actio n set can be repr esented with th e quantu m state and the eigen ac tion can be ob tained by ra ndomly obser ving the simulated quan tum state, wh ich will lead to state co llapse accord ing to th e quantum me asurement postulate. Th e occurr ence probab ility of every eigen action is determined by its co rrespond ing probab ility amplitud e, wh ich is upd ated acc ording to rew ards and value function s. So this app roach represen ts the whole state-action space with the superpo sition o f quantu m state and makes a good trad eoff b etween exploration and exploitation using pro bability . Remark 7: The m erit of QRL is d ual. First, as for simu- lation algorithm o n the traditional c omputer it is an effective algorithm with novel representation and com putation method s. Second, the repr esentation and com putation mod e ar e consis- tent w ith quantu m par allelism and can sp eed up learning with quantum com puters or quantu m gates. I V . A N A L Y S I S O F Q R L In this section, we d iscuss some theore tical pro perties of QRL algorithms and provide some ad vice from the point of view o f eng ineering. Four major r esults are p resented: (1) an asymptotic con vergence propo sition for QRL algo rithms, (2 ) the op timality an d stoch astic algo rithm, (3 ) good balancing between explor ation and exploitation, and (4) physical r eal- ization. From th e follo wing analysis, it is obvious tha t Q RL shows muc h better p erforma nce than other m ethods when the searching space beco mes very large. A. Con ver gence of QRL In QRL we use the tem poral d ifference (TD) pre diction f or the state value upd ating, an d T D algorithm has been proved to conv erge for absorbing Markov ch ain [4] when the learn ing rate is nonn egativ e and degressiv e. T o g enerally consider the conv ergence results of QRL, we h ave Proposition 2. Pr o position 2 (Conver gen c e of QRL): For an y Markov chain, QRL alg orithms conv erge to the optimal state value function V ∗ ( s ) with pr obability 1 under proper explora tion policy whe n the following condition s h old (where α k is learning rate and n onnegative): lim T →∞ T X k =1 α k = ∞ , lim T →∞ T X k =1 α 2 k < ∞ (41) Pr o of: (sketch) Based on the above analysis, QRL is a stochastic iterativ e alg orithm. Bertseka s and Tsitsiklis have verified the convergence of stochastic itera ti ve alg orithms [3] when (41) ho lds. In fact many traditio nal RL algor ithms h av e been proved to be stochastic iterative algor ithms [ 3], [4], [ 47] and QRL is th e same as trad itional RL, and main differences lie in: (1) Ex ploration policy is b ased on th e collap se postulate o f quantum measuremen t while being observed; (2) T his k ind o f algorithms is carried out by q uantum parallelism, which means we update all states simultaneo usly and QRL is a synchro nous learn ing algorithm. So the modification of RL d oes n ot affect the char acteristic of co n vergence and QRL algo rithm converges when (41) holds. B. Optimality and stochastic algorithm Most quantum algorithms a re stochastic algorithms which can giv e th e correct decision-mak ing with pro bability 1- ǫ 8 ( ǫ > 0 , close to 0) afte r several times of repea ted com puting [23], [25]. As for q uantum reinfo rcement learning algorithm s, optimal p olicies are acqu ired by the collapse of quantum system and we will analyz e the optim ality of these policies from two aspects as f ollows. 1) QRL implemented by real qu antum appa ratuses: When QRL alg orithms a re implem ented by rea l quan tum appar a- tuses, the agent’ s strategy is giv en by the collap se of corre- sponding quan tum system accor ding to prob ability amplitud e. QRL algorithm s can not guarantee the optimality of every strategy , but it can give the optima l decision -makin g with the p robability app roximatin g to 1 b y repeatin g comp utation se veral times. Suppose that th e agent g iv es an optimal strategy with the prob ability 1 − ǫ after th e a gent h as w ell learned (state value function co n verges to V ∗ ( s ) ). For ǫ ∈ (0 , 1) , the err or pro bability is ǫ d by r epeating d times. Hence the agent will g iv e th e op timal strategy with th e proba bility o f 1 − ǫ d by rep eating the comp utation for d tim es. The QRL algorithm s on real quantu m appar atuses ar e still effectiv e d ue to th e p owerful comp uting capab ility of quan tum system. Our current work h as b een focused on simulating QRL algorithms on the traditiona l c omputer which also bear th e charac teristics inspired by q uantum systems. 2) Simulating QRL on the tradition a l co mputer: As men- tioned above, in this p aper most work has been done to develop this kind of novel QRL alg orithms b y simulating on the traditional comp uter . But in tradition al RL theory , researc hers have argued that even if we h av e a co mplete and accura te model of the en v ironmen t’ s dynamics, it is usually not possible to simply compu te an op timal policy by solv ing the Bellma n optimality equatio n [1]. What’ s the fact about QRL? I n QRL, the optimal v alue fu nctions and o ptimal policies a re defined in the sam e way as tradition al RL. The difference lies in the representatio n and computing mode. Th e policy is probabilistic instead o f being definite using prob ability amplitude, which makes it mor e e ffecti ve and safer . But it is still o bvious that simulating QRL on the traditional compu ter can not sp eed up learning in expon ential scale since the quan tum parallelism is not r eally e xecuted th rough real ph ysical system s. What’ s more, wh en m ore p owerful compu tation is available, the agent will lea rn m uch better . Then we m ay fall back on ph ysical realization of q uantum computatio n again. C. Balancin g between exploration a nd exploitation One widely used action selection scheme is ǫ -greedy [48], [49], where the best actio n is selected with pro bability ( 1 − ǫ ) and a random action is selected with proba bility ǫ ( ǫ ∈ (0 , 1) ) . The exploration probab ility ǫ can b e reduced over time, wh ich moves the agen t from exploration to exploitatio n. The ǫ -greedy method is simple and e ffecti ve but it has on e drawback that when it explor es it chooses equally amon g all actions. This means tha t it m akes no difference to choose the worst action or the next-to-b est ac tion. Another prob lem is that it is difficult to ch oose a p roper par ameter ǫ which can offer an o ptimal balancing between exp loration and explo itation. Another kind of action selection scheme is Boltzman n exploration (inclu ding Sof tmax action selection method) [ 1], [48], [49]. It uses a positive par ameter τ called the temper - atur e an d cho oses ac tion with th e p robab ility propo rtional to e Q ( s, a ) /τ . It can m ove fr om exploratio n to explo itation by adjusting the “temperature” parameter τ . It is natural to sample actions ac cording to this distribution, but it is very difficult to set and adjust a good par ameter τ . Th ere are also similar problem s with sim ulated annealing (SA) m ethods [50]. W e have intro duced the action selecting strategy of QRL in Section II I, which is called collapse action selection meth od. The agent does not bother about selecting a prop er actio n consciously . The action selecting pr ocess is just accomplished by the f undamen tal ph enomen on that it will n aturally collap se to an eigen action when a n action ( represented by quan tum superpo sition state) is measured . I n the learn ing pr ocess, the agent can explor e mor e effectively sinc e th e state and actio n can lie in the superposition state thro ugh parallel updatin g. When an actio n is observed, it will collap se to an eigen actio n with a cer tain proba bility . Hen ce QRL alg orithm is essentially a kin d of p robab ility algorithm. Howe ver , it is greatly different from classical p robability since c lassical algorithm s f orever exclude each o ther for many r esults, but in QRL algo rithm it is possible for many resu lts to interfere with each othe r to yield som e glob al in formatio n th rough some specific quan tum gates such as Hadmard gates. Com pared with other exploration strategy , this me chanism leads to a better balan cing between exploration a nd exploitation. In th is p aper, the simulated results will show that th e action selection method using the collapse phenomenon is very extraordinar y and e ffecti ve. More importan t, it is co nsistent with the p hysical qua ntum system, which m akes it mo re natural, and the me chanism of QRL has th e potential to be implemented by real quantum systems. D. P hysical r ealization As a quan tum algorith m, the physical realization of QRL is also f easible since th e two main operation s o ccur in prepa ring the equ ally weighted sup erposition state for initializing th e quantum system a nd carr ying out a cer tain times o f Grover iterations for up dating proba bility amplitud e accordin g to rew ards and value function s. These are the same ope rations needed in the Gr over algorithm. They ca n be accom plished using d ifferent comb inations of Hadamard g ates and phase gates. So th e p hysical r ealization of QRL h as n o difficulty in princip le. Moreover , the experimental implementation s of the Gr over algorithm also demonstrate th e feasibility for th e physical realization of o ur QRL algo rithm. V . E X P E R I M E N T S T o ev aluate QRL algo rithm in pr actice, con sider the typ ical gridworld examp le. The gr idworld environment is as shown in Fig. 4 and eac h cell of the grid cor responds to an individual state (eigen state) o f the environments. Fro m any state th e agent can perfor m one of four primary actions (eigen actions): up, down, left and right, and actions that would lead into a blocked cell are not executed. The task o f th e alg orithms is to find an o ptimal po licy which will let the ag ent move from start point S to goal p oint G with minim ized cost (o r maximize d 9 Fig. 4. T he exa mple is a gridworld en vironme nt with cell-to-c ell actions (up, down, left and right). T he labels S and G indic ate the initia l state and the goal in the simulated experiment described in the tex t. rew ards). An episode is defined as one time of learning process when the agent mov es fro m the s tart state to th e goal state. But wh en the ag ent can not fin d the goal state in a maximum steps (or a period of time), this episod e will be terminated an d start ano ther episode from the start state again. So when th e agent finds an o ptimal policy thro ugh learning, the num ber o f moving steps for one episode will r educe to a minim um one. A. Experimental set-up In this 20 × 20 (0 ∼ 19 ) gr idworld, the initial state S and the goal state G is cell(1,1) and cell(18,18) and b efore learning the agent has no infor mation abo ut the environmen t at a ll. Once th e agent fin ds the goal state it receives a reward of r = 10 0 and then en ds th is episod e. All steps a re pun ished by a rew ard of r = − 1 . T he discount factor γ is set to 0 .99 and all of the state values V(s) are initialized as V = 0 for all the algorithm s that we have carried o ut. In the fir st experiment, we com pare QRL alg orithm with TD(0 ) and we also demon strate the expected result on a qu antum computer theoretically . In the secon d experime nt, we gi ve o ut som e results of QRL algor ithm with different lear ning rates. For the action selection policy of TD algorithm, we use ǫ -greedy policy ( ǫ = 0 . 01 ), that is to say , the age nt executes the “g ood” action with probability 1 − ǫ a nd chooses o ther action s with an equal p robability . As for QRL, the action selecting policy is o bviously different from traditio nal RL algorithm s, which is inspired by the collapse postulate of quan tum measurement. The value of | C a | 2 is u sed to denote th e probab ility o f an action defined as f ( s ) = | a ( n ) s i = P 11 ··· 1 a =00 ··· 0 C a | a i . For the four cell-to -cell actions, i. e. fou r eig en action s up, down, left and right, | C a | 2 is initialized unif ormly . B. Experimental r esults and ana lysis Learning per forman ce for QRL algorithm com pared w ith TD algorithm in tr aditional RL is plo tted in Fig. 5, w here the cases with the good perf orman ce ar e chosen for both of the QRL and TD algorith ms. As sho wn in Fig. 5, the good cases in this gridworld example ar e respectively TD algor ithm with the learning rate of α = 0 . 01 and QRL algo rithm with α = 0 . 06 . T he horizo ntal axis rep resents the episode in the learning process and the n umber of steps required is corresp onding ly described by the vertical coor dinate. W e observe th at QRL alg orithm is also an effectiv e algo rithm on the tra ditional compu ter although it is in spired by the q uantum mechanical system an d is de signed for q uantum com puters in the futur e. For their r espective rather goo d cases in Fig. 5 , QRL explores m ore than TD algo rithm at the b eginning o f learning phase, but it learns much fast er and guarantees a better balancing between explo ration and exploitation . In ad dition, it is mu ch easier to tun e the parameters for QRL algorithm s than for traditional ones. If the re al quantum par allelism is used, we can o btain the esti mated theoretical resu lts. What’ s more im portant, acc ording to the estimated theoretical results, QRL has g reat po tential of powerful computatio n pr ovided that the qu antum co mputer (or related quantum app aratuses) is available in the future, which will lead to a mor e effecti ve approa ch fo r the existing pro blems of lea rning in com plex unknown environments. Furthermo re, in th e follo wing comparison e xperimen ts we giv e the results of T D(0) algo rithm in QRL and RL algo rithms with different learning r ates, respectively . I n Fig. 6 it illustrates the re sults of QRL alg orithms with different learning rates: α (alpha), f rom 0.01 to 0 .11, and to giv e a particular de scription of th e learn ing pro cess, we r ecord every learning episodes. From these figu res, it can been con cluded that giv en a proper learning rate ( 0 . 0 2 ≤ alpha ≤ 0 . 10 ) th is alg orithm learns fast and explores much at the beginn ing phase, and then s teadily conv erges to the optimal po licy that costs 36 steps to th e goal state G . As the learning rate incr eases from 0.0 2 to 0 .09, this algorithm learns faster . When th e learn ing rate is 0.01 or smaller , it explores more but learns very slow , so the lear ning process conv erges very slowly . Compared with the result of TD in Fig. 5, we find that the simulation result of QRL on the classical co mputer does no t sh ow ad vantageous when the learning rate is small ( alpha ≤ 0 . 01 ). On the other h and, when the learning rate is 0.11 or above, it can not conv erge to the op timal policy becau se it vib rates with too large lea rning rate when the p olicy is near th e optim al policy . Fig. 7 shows the perfor mance of TD(0 ) alg orithm, and we can see that the learning process converges with the learnin g rate o f 0.01 . Bu t when the lear ning rate is bigg er (alph a=0.02 , 0.03 or bigger), it becom es very hard for us to make it conv erge to th e o ptimal policy within 100 00 episodes. Anyway fr om Fig. 6 and Fig. 7, we can see that the co n vergence rang e of QRL algorithm is much larger th an that of tr aditional TD(0 ) alg orithm. All th e results show that QRL algorith m is effectiv e and excels tradition al RL algorithms in the f ollowing three main aspects: ( 1) Actio n selecting po licy makes a good tr adeoff between exploration and explo itation usin g p robab ility , wh ich 10 Fig. 5. Performance of QRL in the exa mple of a gridworld env ironment compared with TD algori thm ( ǫ -greedy policy ) for their respect i ve good cases, and the expected theoretica l result on a quantum computer is also demonstrated. speeds up the learn ing and gua rantees the searching over th e whole state-action space as well. (2) Representatio n is based on the su perposition principle of quantum mechan ics and the updating proc ess is carried ou t throug h qu antum parallelism, which will b e mu ch more pro minent in the fu ture when practical qu antum appar atus comes into u se instead o f b eing simulated o n the traditional co mputers. (3 ) Comp ared with the experim ental results in Ref. [5 1], where th e simulation en vironmen t is a 13 × 1 3 (0 ∼ 12) gr idworld, we c an see that when the state spac e is getting larger, the perform ance of QRL is getting better than trad itional RL in simu lated experimen ts. V I . D I S C U S S I O N The key contribution of th is paper is a novel reinfo rcement learning fr amework called q uantum reinf orcemen t learn ing that integrates quantu m mechanic s cha racteristics a nd rein- forcemen t learning theories. I n this section some a ssociated problem s of QRL o n the trad itional com puter are discu ssed and some future work regar ded as impo rtant is als o pointed out. Although it is a long w ay for imp lementing s uch compli- cated qu antum sy stems as QRL by ph ysical quantu m systems, the simulated versio n of Q RL on the tr aditional compu ter has been p roved effecti ve and also excels standard RL method s in se veral asp ects. T o improve this approach some issues of future work is laid ou t as follows, wh ich we dee m to be imp ortant. • Mo del of en vironments An app ropriate m odel o f the en vironmen t will make problem -solving much easier and more efficient. This is true f or most o f the RL algo rithms. Howe ver , to mode l environments accurately and simp ly is a tradeoff pro blem. As for QRL, this p roblem should be considered sligh tly differently due to so me of its specialities. • Re presentations Th e rep resentations for QRL alg orithm accordin g to different kin ds of p roblems would be n atu- rally of interest ones when a lear ning system is design ed. In this pap er , we mainly discuss pr oblems with discrete states and actions and a natur al qu estion is how to extend QRL to the p roblem s with co ntinuou s states an d actions effecti vely . • F unction approximation and genera lization Gen eral- ization is necessary f or RL systems to b e applied to artificial intelligence and most eng ineering app lications. Function approx imation is an im portant appr oach to acquire genera lization. As fo r QRL, this issue will b e a rather ch allenging task and fu nction appro ximation should be co nsidered with the special compu tation mode of QRL. • Theo r y QRL is a ne w lea rning frame work that is dif ferent from standard RL in several aspects, such as r epresenta- tion, action selection , exploration policy , u pdating style, 11 Fig. 6. Comparison of QRL algorit hms with diffe rent learni ng rates (alpha = 0 . 01 ∼ 0 . 11 ). Fig. 7. Comparison of TD(0) algori thms with diffe rent learning rates (alpha = 0.01, 0.02, 0.03). 12 etc. So there is a lo t of theoretical work to do to take most advantage of it, especially to analyze the complexity of the QRL algo rithm and impr ove its re presentation and computatio n. • Mo re applicat ions Besides m ore theoretical re search, a tremen dous op portun ity to ap ply QRL algo rithms to a r ange of problem s is n eeded to testify and imp rove this kind o f learning alg orithms, especially in unkn own probab ilistic environments and large learning space. Anyway we stro ngly believe that QRL ap proach es and related techniques will be promising fo r ag ent learning in large scale unkn own environment. This new idea o f app lying quantum ch aracteristics will also inspire the research in the area of mach ine learning . V I I . C O N C L U D I N G R E M A R K S In this p aper, QRL is prop osed based on the concepts and theo ries of q uantum computatio n in the lig ht of the existing problems in RL alg orithms such as tradeo ff between exploration and exploitation, low learning speed , etc. Inspired by state superposition pr inciple, we introd uce a fr amew ork o f value upd ating a lgorithm. The state (action) in trad itional RL is looked upon as the eigen state (eigen action) in QRL. The state (action) set can be rep resented by the quantum superposition state a nd th e eig en state (eig en actio n) can be obtain ed by r an- domly observin g th e simulated quan tum state according to the collapse postulate of qu antum m easuremen t. The prob ability of eigen state ( eigen a ction) is d etermined b y the p robab ility amplitude, which is updated according to rew ards and value function s. So it makes a go od tradeoff between exploration and exploitation and can speed u p learnin g as well. At the same tim e this n ovel idea will promote re lated theoretical a nd technical research . On the theoretical side, it gives us more in spiration to look fo r new p aradigm s of machin e le arning to acqu ire better perfor mance. It also in troduces the latest development o f fundam ental science, such as p hysics and mathematics, to th e area of artificial intelligence and pr omotes the development of th ose subjec ts as well. Espec ially the repre sentation and essence of q uantum c omputatio n are different from classical computatio n and many aspects o f q uantum computatio n are likely to evolve. Sooner or later ma chine learn ing will also be pr ofoun dly influen ced by quantum comp utation theory . W e have d emonstrated the applicability of qu antum co mputation to ma chine learn ing and more interesting r esults are expected in the nea r future. On the technical sid e, the results of simulated exper iments demonstra te the feasibility of this algorithm and show its superiority for the learning problems with hu ge state spa ces in unkn own probab ilistic environments. With the p rogress of quantum tech nology , some fu ndamen tal qu antum o perations are being realize d via nu clear magnetic resonan ce, quantum optics, cavity-QED and ion tr ap. Sin ce the ph ysical r ealization of QRL mainly needs Had amard gates and ph ase gates and both of th em are relativ ely easy to b e implemen ted in quan tum computatio n, ou r work also p resents a n ew task to imp lement QRL using p ractical quan tum systems for qu antum compu - tation and will simultane ously promo te related experimen tal research [5 1]. Once QRL beco mes realizable on real physical systems, it can be effectively used to q uantum robo t learning for accom plishing som e significant tasks [5 2], [53]. Quantum computatio n and machin e learning are b oth the study of the informatio n p rocessing tasks. The two r esearch fields hav e rap idly gro wn so that it g iv es birth to the combin ing of tradition al learning algo rithms a nd quan tum computa tion methods, which will in fluence represen tation and lear ning mechanism, and many difficult problem s cou ld be solved approp riately in a n ew way . Moreover , this idea also pioneers a new field f or qu antum c omputatio n and artificial intelligence [52], [53], and some efficient applications or h idden advan- tages of q uantum compu tation are pr obably approach ed f rom the angle of lear ning and intelligen ce. A C K N O W L E D G M E N T The authors would like to th ank two anonymou s r evie wers, Dr . Bo Qi and the Associate Edito r of IEEE T rans. SM CB for construc ti ve co mments an d suggestions w hich help clarify se veral concep ts in our origin al manuscr ipt and ha ve g reatly improved th is paper . D. Dong also wishe s to thank Prof. Lei Guo and Dr . Zairong Xi fo r h elpful discussion s. R E F E R E N C E S [1] R. Sutton and A. G. Barto, R einfor ce ment Learning: A n Intr oducti on . Cambridge , MA: MIT Press, 1998. [2] L. P . Kaelbling, M. L. Littman and A. W . Moore, “Reinforcement learni ng: A surve y , ” Jou rnal of Artificial Intellig ence Resear ch , vol.4, pp.237-287, 1996. [3] D. P . Bertsekas and J. N. Tsitsiklis, Neur o-Dynamic Pro gra mming . Belmont, MA: Athena Scientific, 1996. [4] R. Sutton, “Learnin g to predict by the methods of temporal dif ferenc e, ” Mach ine Learning , vol.3, pp.9-44, 1988. [5] C. W atki ns and P . Dayan, “Q-learni ng, ” Mach ine Learning , vol.8, pp.279-292, 1992. [6] D. V engero v , N. Bambos and H. Berenj i, “ A fuzzy reinforc ement learni ng approach to control in wirele ss transmitters, ” IE EE T ransactions on Systems Man and Cybernetics B , vol.35, pp.768-778, 2005. [7] H. R. Beom and H. S. Cho, “ A sensor-based navigati on for a mobile robot using fuzzy logic and reinforceme nt learni ng, ” IEEE T ransactions on Systems Man and Cybernetics , vol.25, pp.464-477, 1995. [8] C. I. Connolly , “Harmonic functio ns and collision probabiliti es, ” Inter- national Journal of R obotics Researc h , vol.16, no.4, pp.497-507, 1997. [9] W . D. Smart and L. P . Kaelbling, “Effecti ve reinforc ement learni ng for mobile robots, ” in Proce edings of the IEEE International Confer enc e on Robotics and Automati on , pp.3404-3410, 2002. [10] T . K ondo and K. Ito, “ A reinforce ment learning with evo lution ary state recruit ment strategy for autonomous mobile robots control, ” Robotics and Autonomou s Systems , vol.46, pp.111-124, 2004. [11] M. W ierin g and J. Schmidhuber , “HQ-Learning, ” Adap tive Behavior , vol.6, pp.219-246, 1997. [12] A. G. Barto and S. Mahanev an, “Rece nt advan ces in hierarc hical reinforc ement learning, ” Discre te Event Dynamic Systems: Theory and Applicat ions , vol.13, pp.41-77, 2003. [13] R. Sutton, D. Precup and S. Singh, “Between MDPs and semi-MDPs: A frame work for temporal abstracti on in reinforcement learning, ” Artificial Intell ige nce , vol.112, pp.181-211, 1999. [14] T . G. Dietteri ch, “Hi erarchi cal reinforcement learning with the Maxq v alue function decomposition, ” Journal of Artificial Intellige nce Re- sear ch , vol.13, pp.227-303, 2000. [15] G. T heocha rous, Hierar ch ical Learning and Planning in P artially Ob- servable Markov Decision Processe s . Doctor thesis, Michiga n State Uni ve rsity , USA, 2002. [16] A. J. Sm ith, “ Applicatio ns of the self-or ganisin g m ap to reinforcement learni ng, ” Neural Networks , vol.15, pp.1107-1124, 2002. [17] P . Y . Glorennec and L. Jouffe , “Fuzzy Q-learning, ” in Proc eedings of the Sixth IEEE International Confer ence on Fuzzy Systems , pp.659-662, IEEE Press, 1997. 13 [18] S. G. Tzafestas and G. G. Rigatos, “Fuzzy Reinforce ment Learning Con- trol for Complian ce T asks of Robotic Manipul ators, ” IE EE T ran saction on System, Man, and Cybernet ics B , vol.32, no. 1, pp.107-113, 2002. [19] M. J. Er and C. De ng, “Onli ne Tuni ng of Fuzzy Infere nce Systems Using Dynamic Fuzzy Q-Learning, ” IEEE Tr ansact ion on System, Man, and Cybernet ics B , vol.34, no. 3, pp.1478-1489, 2004. [20] C. Chen, H. Li and D. Dong, “Hybrid control for autono mous mobile robot navigatio n using hierarch ical Q -learni ng, ” IEEE Robotics and Automat ion Magazine , vol.15, no. 2, pp.37-47, 2008. [21] S. Whiteson and P . Stone, “Ev oluti onary functio n approxima tion for reinforc ement learni ng, ” Journal of Machine Learning Resear ch , vol.7, pp.877-917, 2006. [22] M. Kaya and R. Alhajj, “ A novel approa ch to multiage nt reinforcemen t learni ng: Utilizi ng OLAP mining in the learning process, ” IEEE T rans- actions on Systems Man and Cybernetics C , vol.35, pp. 582-590, 2005. [23] P . W . Shor, “ Algorithms for quantum computati on: discret e logarithms and factori ng, ” in P r ocee dings of the 35th Annual Symposium on F oun- dations of Computer Scienc e , pp.124-134, IEEE Press, L os Alamitos, CA, 1994. [24] A. Ek ert and R. Jozsa, “Qua ntum computa tion and Shor’ s fa ctoring algorit hm, ” Revie ws of Modern Physics , vol.68, pp.733-753, 1996. [25] L. K. Grover , “ A fast quantum mechanical algorithm for database search, ” i n Proc eeding s of the 28th A nnual ACM Symposium on the Theory of Computation , pp.212-219, ACM Press, New Y ork, 1996. [26] L. K. Grover , “Quantum mechani cs helps in searchi ng for a needle in a haystack , ” Physical Revie w Letter s , vol .79, pp.325-327, 1997. [27] L. M. K. V andersype n, M. Steffe n, G. Breyt a, C. S. Y a nnoni, M. H. Sher - wood and I. L. Chuang, “Experimental realiza tion of Shor’ s quantu m fac toring algorith m using nuclear magnetic resonanc e, ” Nature , vol.414, pp.883-887, 2001. [28] I. L. Chuang, N. Gershenfeld and M. Kubine c, “Experiment al imple- mentati on of fast quantum searching, ” Physical R evi ew Letters , vol.80, pp.3408-3411, 1998. [29] J. A. Jones, “Fast searches with nuclear magnetic resonance computers, ” Scienc e , vol.280 , pp.229-229, 1998. [30] J. A. Jones, M. Mosca and R. H. Hansen, “Implementatio n of a quantum Search algorithm on a quantu m computer , ” Nature , vol.393, pp.344-346, 1998. [31] P . G. Kwiat, J. R. Mitchel l, P . D. D. Schwindt and A. G. White, “Grov er’ s search algorit hm: an optica l approach, ” J ournal of Modern Optics , vol.47, pp.257-266, 2000. [32] M. O. Scully and M. S. Zubairy , “Quantum optical implementati on of Grov er’ s algorithm, ” P r ocee dings of the National Academy of Sciences of the United States of America , vol.98, pp.9490-9493, 2001. [33] D. V entura and T . Ma rtinez , “Quantum associati ve m emory , ” Information Scienc es , vol.124, pp.273-296, 2000. [34] A. Narayanan and T . Menneer , “Quant um artificial neural netw ork archit ecture s and components, ” Informati on Science s , vol.128, pp.231- 255, 2000. [35] S. Kak, “On quantum neural computing, ” Information Science s , vol.83, pp.143-160, 1995. [36] N. Kouda, N. Matsui, H. Nishimura and F . Peper , “Qubit neural network and its learning ef ficien cy , ” Neural Computing and Applicati ons , vol.14, pp.114-121, 2005. [37] E. C. Beh rman, L. R. Nash, J. E . Steck, V . G. Chandra shekar and S. R. Skinner , “Simulati ons of quantum neural networks, ” Information Scienc es , vol.128, pp.257-269, 2000. [38] G. G. Rigatos and S. G. Tzafesta s, “Parall eliza tion of a fuzzy control algorit hm using quantum computation, ” IEEE T ransac tions on F uzzy Systems , vol .10, no.4, pp.451-460, 2002. [39] M. Sahin, U. Atav and M. T omak, “Quantum geneti c algorit hm m ethod in self-consiste nt electronic s tructur e calcul ations of a quantum dot with many elec trons, ” Inte rnationa l J ournal of Modern P hysics C , vol.16, no.9, pp.1379-1393, 2005. [40] T . Hogg and D . Portnov , “Quantum optimization, ” Informati on Sciences , vol.128 , pp.181-197, 2000. [41] S. Nagulesw aran and L . B. W hite, “Quantum s earch in stochasti c plannin g, ” Pro ceedi ngs of SPIE , vol.5846, pp.34-45, 2005. [42] D. Dong, C. Chen and Z. Chen, “Quantum reinforce ment learni ng, ” in Pr oceed ings of Fi rst International Confer ence on Natural Computation , Lectur e Notes in Computer Science , vol.3611, pp.686-689, 2005. [43] J. Preskill, Physics 229: A dvanced Mathematical Method s of Physics–Quant um Informatio n and Comp utation . Californi a Institut e of T ec hnology , 1998. A v ail able electro nical ly via http:// www .theory .caltec h.edu/people/pre skill/ph229/ [44] M. A. Nielsen and I. L. Chuang, Quantum Computati on and Quantum Informatio n . Cambridge, England: Cambridge Unive rsity Press, 2000. [45] C. Chen, D. Dong and Z. Chen, “Quantum computat ion for actio n se- lecti on using reinforc ement learn ing, ” Internat ional Journal of Quantum Informatio n , vol.4, no.6, pp.1071-1083, 2006. [46] M. Boyer , G. Brassard and P . Høyer , “Ti ght bounds on quantum searchi ng, ” F ortsc hritt e Der P hysik-Pr ogress of Physics , vol.46, pp.493- 506, 1998. [47] E. Even-Dar and Y . Mansour , “Learning rates for Q-learning, ” Journ al of Mac hine Learning Resear ch , vol.5, pp.1-25, 2003. [48] T . S. Dahl, M. J. Mataric and G. S. S ukhatme, “Emergent Robot Diff er- entia tion for Distribu ted Multi-Ro bot T ask Alloca tion, ” in Proc eeding s of the 7th Internationa l Symposium on Distributed Autonomou s Robotic Systems , pp.191-200, 2004. [49] J. V ermorel and M. Mohri, “Multi-ar med Bandit Algorith ms and Em - pirica l Ev aluat ion, ” Lectur e Notes i n A rtificia l Inte llig ence , vol.3720, pp.437-448, 2005. [50] M. Guo, Y . L iu and J. Malec, “ A New Q-Learning Algorithm Based on the Metropol is Crite rion, ” IEEE T ransaction on System, Man, and Cybernet ics B , vol.34, no. 5, pp.2140-2143, 2004. [51] D. Dong, C. Chen, Z. Chen and C. Zhang, “Quantum mechanics helps in learning for more intelli gent robots, ” Chinese Physics Letters , vol.23, pp.1691-1694, 2006. [52] D. Dong, C. Chen, C. Z hang and Z. Chen, “Quant um robot: structure, algorit hms and applicati ons, ” Robotica , vol.24, pp.513-521, 2006. [53] P . Beniof f, “Quantum Robots and En viron ments”, Physical Revie w A , vol.58, pp.893-904, 1998.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment